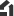
- 商品検索:カテゴリ
- Lightelligence製 シリコンフォトニクス技術
- Hummingbird oNOC
高密度光インターコネクト技術搭載プロセッサ
製品名
Hummingbird oNOC
製品名
Hummingbird oNOC
チップとインターポーザ間を “光” で結ぶ新技術 “oNOC”搭載
チップ間通信の低遅延、低消費電力化を実現





- "メモリの壁"を打ち破る新しいインターコネクト技術“oNOC”
- 高密度導波路による光速でのチップ間通信を実現
- "oNOC"プラットフォームを実装した評価プロセッサHummingbird oNOC
- 64コアプロセッサによる低レイテンシAIアクセラレート
- SDKはTensorFlowフレームワークに対応
- メッシュやトーラスなど多彩なネットワークトポロジでグラフ処理可能
Hummingbird oNOCプロセッサは、Lightelligence社が新たに開発したインターコネクト技術“oNOC”を搭載。各演算チップ間の接続回路をシリコンフォトニクスで構成されたoNOC回路へ置き換えているため、“光る”だけでコア間のデータ通信が完了します。また、64コアの各コア間は全対全ブロードキャスト技術で相互接続されており、処理するグラフ構造に合わせて各コアが同時並列的にデータへアクセス可能。SDKはTensorFlowフレームワークに対応しており、各種オペレータをネイティブサポート。 高効率なデータアクセスが低レイテンシ、低消費電力でのAI演算を可能にします。
oNOC技術をユーザー独自のプロセッサやSoCへ実装させるカスタム開発も対応可能。チップ間の通信を光インターコネクト技術により効率的に行いたい方はぜひご相談ください。
光インターコネクト技術 “oNOC - Optical Network-on-Chip”

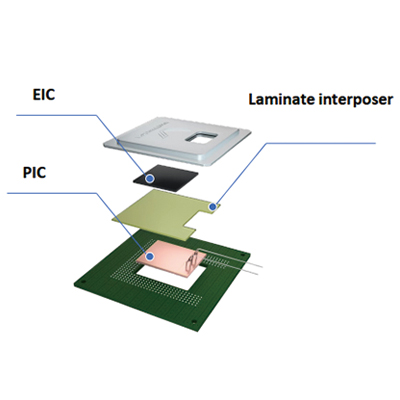
微細加工技術の進歩により半導体の集積密度は年々向上していますが、高度な加工技術の影響で歩留まりが低下してしまうので、近年では大規模回路を大きな1チップに細かく集積するのではなく、各機能を分けてより小型のチップをインターポーザを用いて複数繋げ、大規模回路を構築する手法"チップレット"が採用されています。
ただ、チップ同士を結ぶインターコネクトの配線距離が長いと遅延が大きくなり消費する電力も上がります。また、各チップ同士の通信距離が遠くなるほど遅延が大きくなるため、効率的に全てのチップを利用する事ができず、チップの数を増やしてもパフォーマンスが頭打ちになってしまいます。
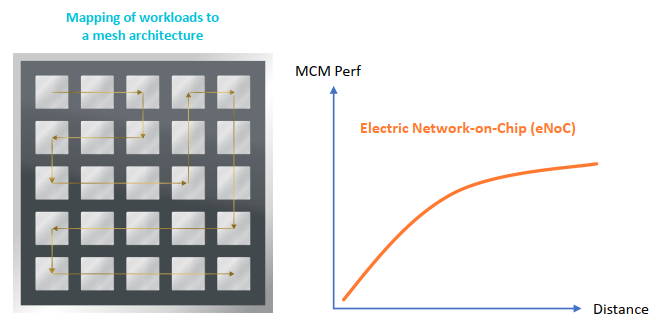
Lightelligence社はこの問題を解決する最適な手法の一つとして、シリコンフォトニクスによるインターコネクト技術"oNOC"を開発しました。
高密度な導波路による光を用いたデータ通信回路により、配線距離による消費電力と遅延の依存問題を解決します。
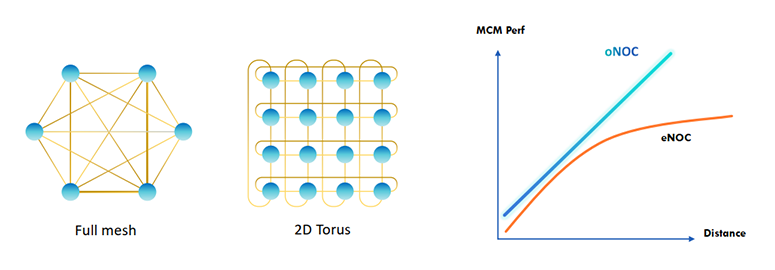
また、光によるインターコネクトは各チップ間のネットワークトポロジも柔軟に対応できるため、隣通しのチップ間通信だけではなくメッシュやトーラスなど多彩な通信パスでのチップ間相互通信が可能になりました。複数のチップをより効率的に利用してデータ処理を行うことでチップ数の増大に対してリニアに性能向上が可能となり、チップレット技術を更に拡張することが可能です。
| Hummingbird oNOCプロセッサ | |
|---|---|
| 演算コア | 64コア |
| 精度 | INT8 |
| オンチップキャッシュ | 38MiB SRAM |
| ECC | SECDEC対応 |
| システムメモリ | 2GB DDR4 SDRAM |
| バスインターフェース | PCI-ExpressGen3 x4 |
| 理論演算能力 | TBD |
| バスインターフェース | PCI-Express 3.0 x4 |
| ボード規格 | フルサイズ(2スロット仕様) |
| 消費電力 | 45W |
| ファンレス | ◯ |
| SDK | LT-SDK |
3次元システムインパッケージ(3D-SiP)
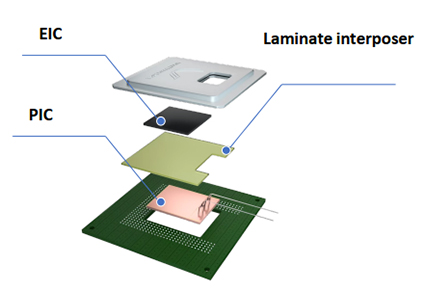
Hummingbird oNOCに搭載されている演算プロセッサは、電子チップ(EIC)、インターポーザ、フォトニックチップ(PIC)の3つの主要コンポーネントを3次元積層技術でパッケージ化しています。EICはキャッシュメモリや演算コアなどを含むデジタル演算を行うチップです。インターポーザはEICとPICを結び各回路に電力を供給します。PICはシリコンフォトニクスで形成された光インターコネクト“oNOC”を実装したチップです。oNOCで張り巡らされた導波路の屈折率を変える事で光の強度を用いたデジタル信号と光アナログ信号の相互変換をPICで行い、光るだけで各EICが相互通信できるので低遅延かつ低消費電力に演算処理が実行可能です。


TensorFlowのフレームワーク準拠
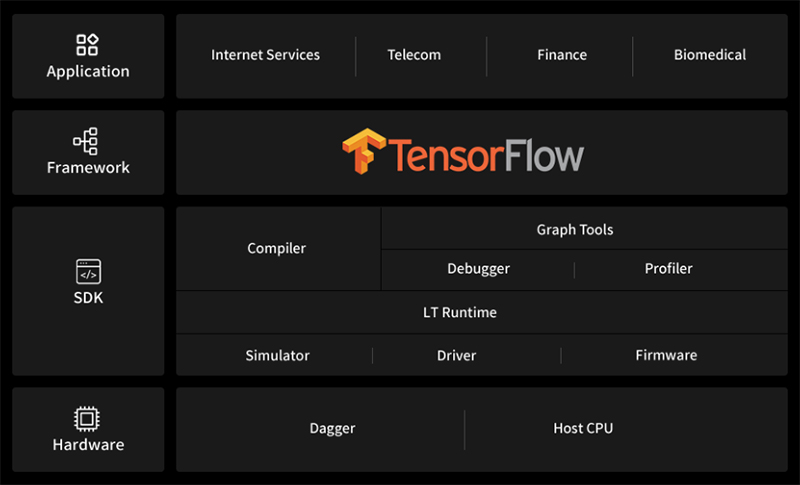
提供SDKの“LT-SDK”はTensorFlowフレームワークをベースにしており、各種オペレータをネイティブサポート。 マルチカードによる推論など、TensorFlowによるグラフ演算を低遅延にアクセラレートします。
- 既存のTensorFlowモデルが利用可能

- ほぼ全てのTensorFlowオペレータをネイティブサポート

- グラフ演算とオペレータ処理を低遅延にアクセラレート

| 商品コード(型番) | 構成/内容 | 価格 | |
|---|---|---|---|
| 評価ボード | Hummingbird oNOC | oNOC評価用AIアクセラレータボード | お問い合わせ |
- 商品検索:カテゴリ
- Lightelligence製 シリコンフォトニクス技術
- Hummingbird oNOC
