
テキストセグメンテーションモデルの作成
テキスト セグメンテーション用のグラフィカル エディタは 2 つの操作を実行します。
- いくつかの異なる方法のいずれかを使用して画像を閾値処理し、すべての文字に対応する単一の前景領域を取得します。
- 前景領域を個々の文字に対応する領域の配列に分割します。
OCR フィルタの使用の詳細については、「マシン ビジョン ガイド: 光学式文字認識」を参照してください。
テキスト抽出を設定するには、次の手順を実行してください:
-
ExtractTextフィルタをプログラムに追加する。

-
inRoi 入力に関心領域を設定します。 この手順は、次の手順を実行する前に必要です。 以下の画像は、サンプル アプリケーションで ROI がどのように選択されたかを示しています。

-
inSegmentationModel 入力の [...] ボタンをクリックして、グラフィカル エディタを開きます。
-
初めて入力するときは、最も一般的な設定を選択してクイックセットアップを完了します。 この例では、均一な背景から黒い非連続テキストを抽出する必要があります。 構成は、これらの要件を満たすように設定されました。

-
クイックセットアップの後、グラフィカルエディタがいくつかのパラメータセットで開始されます。
最良の結果が得られるように、事前設定されたパラメーターを調整します。
-
文字抽出アルゴリズムを構成します。 この場合、しきい値が高すぎるため、下げる必要があります。
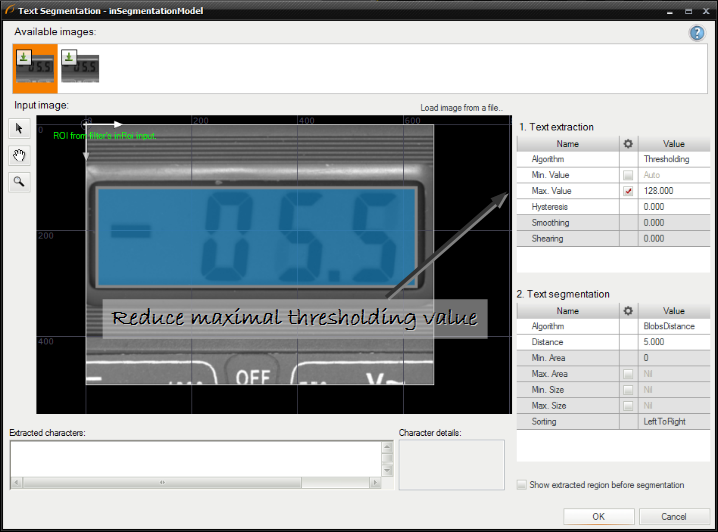
-
文字分割アルゴリズムを選択します。
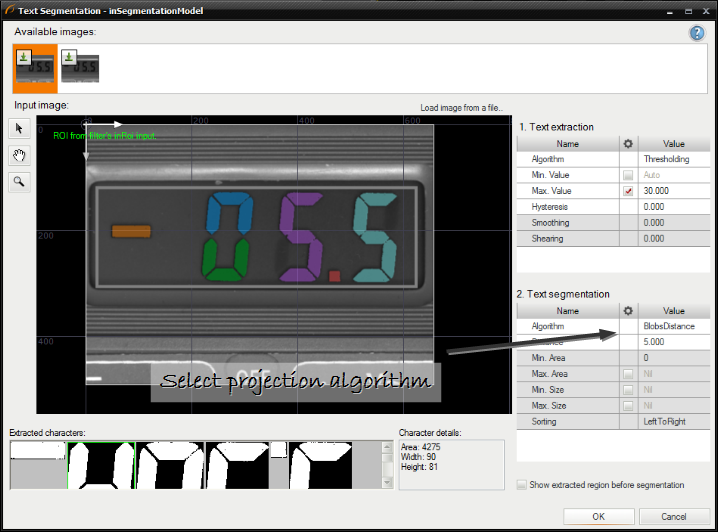
-
文字の最小サイズと最大サイズを設定します。 エディターには、以下のリストでキャラクターが選択されると、キャラクターの寸法が表示されます。
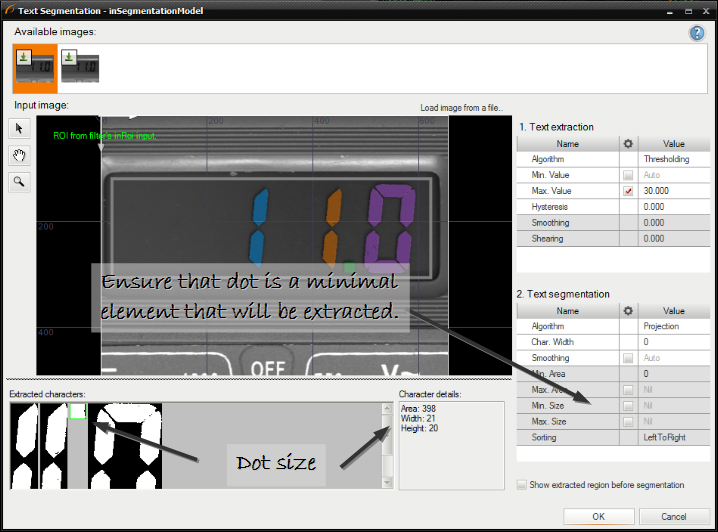
-
文字の並べ替え順序、文字の傾き補正 (せん断)、および画像のスムージングを選択します。 画像の品質が低い場合、スムージングは重要です。

-
利用可能な画像を使用して結果を確認します。
