
テキスト認識モデルの作成
テキスト認識エディターは、領域からテキストを取得するための OCR モデルを作成します。 OCR 技術の詳細については、マシン ビジョン ガイド: 光学式文字認識を参照してください。
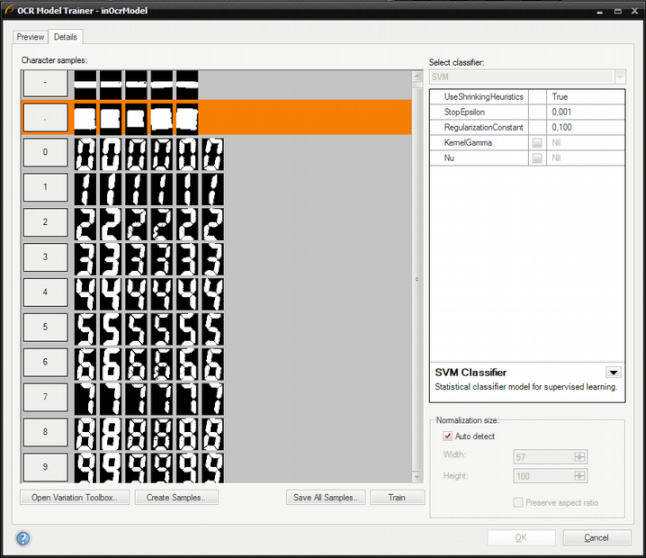
OCR モデルを作成するには、一連の文字を収集する必要があります。 実際のサンプルに基づいてトレーニングした後の認識スコアが低い場合、人為的な文字のバリエーションが作成される可能性があります。
モデルの作成は次の手順で構成されます。
-
実際のサンプルの収集 - エディターを開くとキャラクターが表示され、トレーニング セットに追加できます。
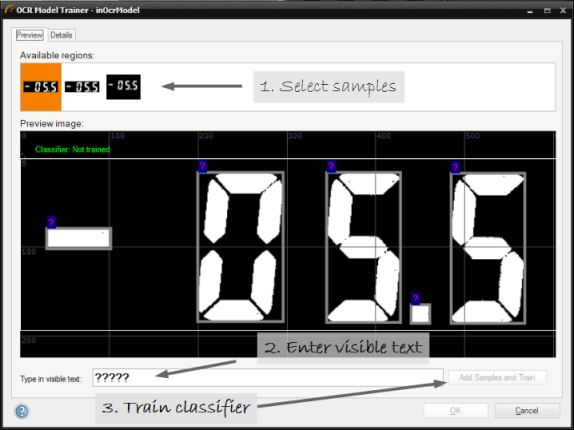
トレーニング後、キャラクターのサンプルが詳細タブで表示されます。
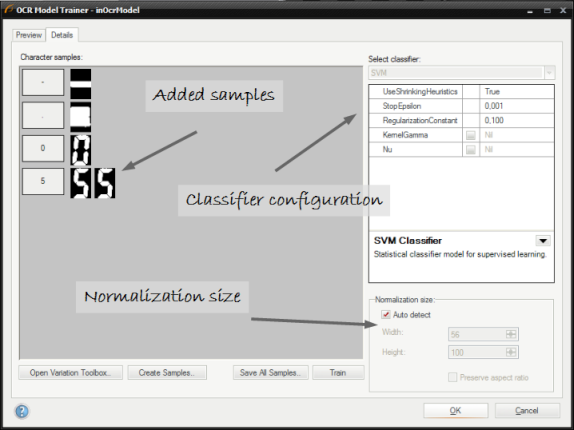
人工サンプルの作成 - 利用可能なサンプルがない場合、ユーザーはシステム フォントを使用してトレーニング セットを作成できます。
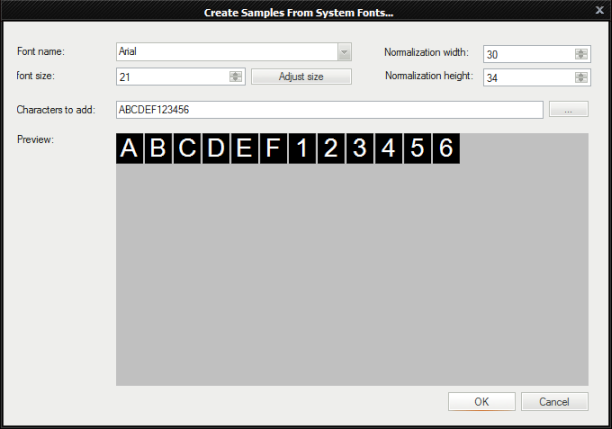
-
キャラクターバリエーションの作成 使用可能なサンプルがもうなく、トレーニング結果が適切でない場合、エディターは既存のサンプルを変更して新しいセットを作成できます。
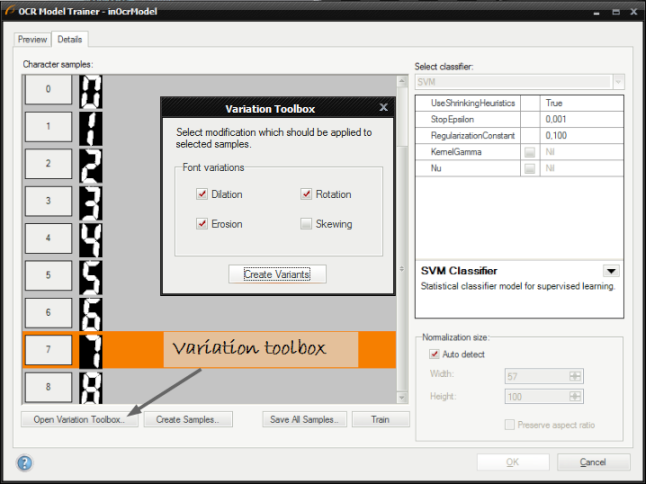
新しいサンプル バリエーションを追加した後のトレーニングセット
-
サンプルの編集 - 収集したサンプルにノイズが含まれている場合、またはその品質が低い場合は、ユーザーが手動で編集できます。 下の画像は、文字「8」を編集して文字「9」を取得する方法を示しています。

注:
- 各トレーニングキャラクターには、これと同じ数のサンプルが必要です。
- 一部の文字が非常に似ている場合、サンプルの数を増やして分類を改善できます。
- 文字サンプルを外部ディレクトリに保存して実験を行うことができます。