
深層学習モデルの作成
Contents:
はじめに
ディープ ラーニング エディタは、DeepModel オブジェクト (トレーニング結果を表す) 専用のグラフィカル ユーザー インターフェイスです。 ユーザーはこのようなエディターを開くたびに、画像の追加または削除、パラメータの調整、新しいトレーニングの実行を行うことができます。
バージョン 4.10 以降、ディープ ラーニング エディターをスタンドアロン アプリケーションとして開くオプションもあり、実稼働環境で新しいイメージを使用してモデルを再トレーニングする場合に特に便利です。
Requirements:
- ディープ ラーニング エディタとフィルタを使用するには、ディープラーニング ライセンスが必要です。
- モデル トレーニングを実行するには、ディープ ラーニング サービスが稼働している必要があります。
現在利用可能な深層学習ツールは次のとおりです:
- 異常検出 – 予期せぬ物体の変化を検出するため。 単純に良いか悪いかをマークしたサンプル画像を使用してトレーニングする
- 特徴検出 – 欠陥領域(表面の傷など)または特徴(医療画像上の血管など)の検出用。 正確にマークされたグラウンドトゥルース領域を伴うサンプル画像を使用してトレーニングされる
- オブジェクトの分類 – 入力画像上で最も目立つオブジェクトの名前またはクラスを識別するため。 予想されるクラス ラベルを伴うサンプル画像を使用してトレーニングされます。
- インスタンスのセグメント化 – シーン内の複数のオブジェクトの位置、セグメンテーション、および分類を同時に実行します。 個々のオブジェクトの正確にマークされた領域を伴うサンプル画像を使用してトレーニングする
- ポイントの位置 – 複数のキーポイントの位置と分類。 予想されるクラスのマークされたポイントを伴うサンプル画像を使用してトレーニングする
- 文字を読み取る – 複数の文字の位置と分類用。 このツールは事前トレーニング済みモデルを使用しており、トレーニングできないため、この記事では説明しません
- オブジェクトの場所 – 複数のオブジェクトの位置と分類。 予想されるクラスのマークされた境界四角形を伴うサンプル画像を使用してトレーニングされます。
これらのツールの技術的な詳細については、マシン ビジョン ガイド: ディープ ラーニングを参照してください。この記事ではトレーニングのグラフィカル ユーザー インターフェイスに焦点を当てています。
ワークフロー
次の方法でディープラーニングエディタを開くことができます。
- Aurora Vision Studio のフィルター:
- プログラムエディターで関連するDLフィルタ (例: DL_DetectFeature または DL_DetectFeature_Deploy) を配置します。
- プロパティに移動します。
- inModelDirectory または inModelId.ModelDirectory パラメータの横にあるボタンをクリックします。
- スタンドアロンのDeep Learning Editor アプリケーション:
- スタンドアロンのDeep Learning Editorアプリケーションを開きます (Aurora Vision Studio インストール フォルダに「DeepLearningEditor.exe」としてあり、[スタート] メニューの Aurora Vision フォルダー、または [ツール] メニューの Aurora Vision Studio アプリケーションにあります)。
- 新しいモデルを作成するか、既存のモデルを使用するかを選択します:
- 新しいモデルの作成: モデルに関連するツールを選択して [OK] を押し、モデルのファイルが含まれる新しいフォルダーを選択または作成して [OK] を押します。
- 既存のモデルの選択: モデル ファイルが含まれるフォルダーに移動します。 そのパスへのパスを書き込むか、フィールドの横にあるボタンをクリックして参照するか、最近のパスがある場合はいずれかを選択します。 次に「OK」を押します。
深層学習モデルの準備プロセスは、通常、次のステップに分かれています。
- 画像を読み込み中 – トレーニング画像をディスクからロードする
- 画像にラベルを付ける – 各トレーニング画像に特徴をマークするかラベルを付ける
- 関心領域の設定 (オプション) – 分析する画像の領域を選択します
- トレーニング パラメータの調整 – 対象のアプリケーションに固有のトレーニング パラメータ、前処理ステップ、拡張機能を選択する
- モデルのトレーニングと結果の分析
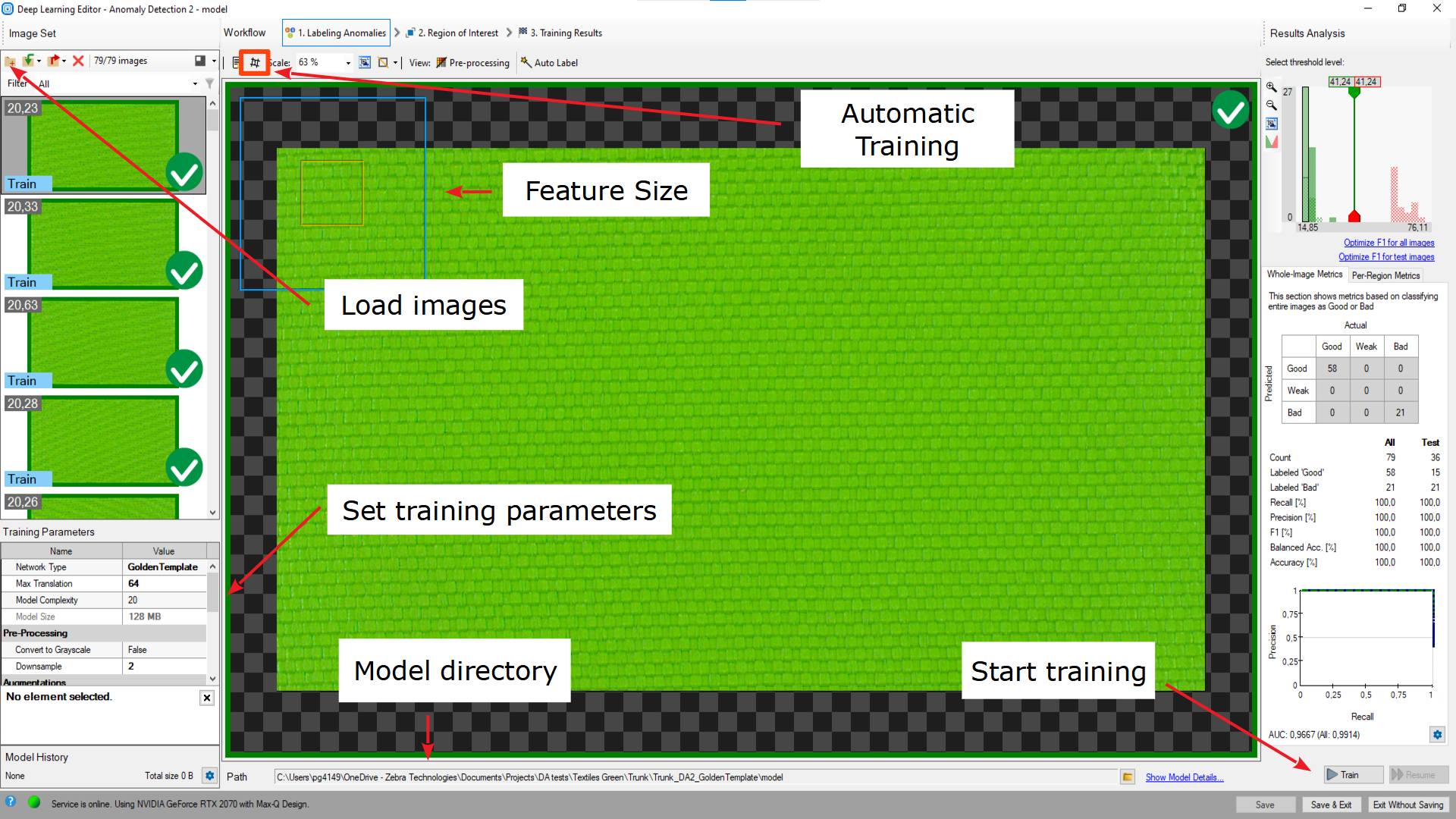
ディープ ラーニング エディターの概要。
重要事項:
- 前処理ボタン – 上部のツールバーにあります。 トレーニング画像に適用された変更を確認できます。 グレースケールまたはダウンサンプリング。
- 現在のモデル ディレクトリ – 下部のツールバーにあります。 別のディレクトリにあるモデルを切り替えたり、実際に作業しているモデルを単に確認したりできます。
- 「モデルの詳細を表示」ボタン – 前のコントロールの隣にあります。 現在のモデルに関する情報を表示し、ファイルに保存できます。

- トレーニングとトレーニング 再開ボタン – トレーニング パラメータの一部を変更した場合に備えて、トレーニングを開始または再開できます。
- 保存ボタン:
- 保存 – 現在のモデルを選択した場所に保存します。
- 保存して 終了 – モデルを保存し、ディープ ラーニング エディタを終了します。
- 保存せずに終了 – エディタは終了しますが、モデルは保存されません。
自動トレーニング ウィンドウを開くボタン – さまざまなパラメータのトレーニング シリーズを準備できます。
どのパラメータ設定が最良の結果をもたらすかわからない場合は、各値の組み合わせを準備して結果を比較できます。
テストパラメータは新しいグリッドの生成を使用して自動的に準備することも、手動で入力することもできます。 パラメータを設定したら、テストを開始する必要があります。
設定と結果はグリッドに 1 つのモデルにつき 1 行で表示されます。
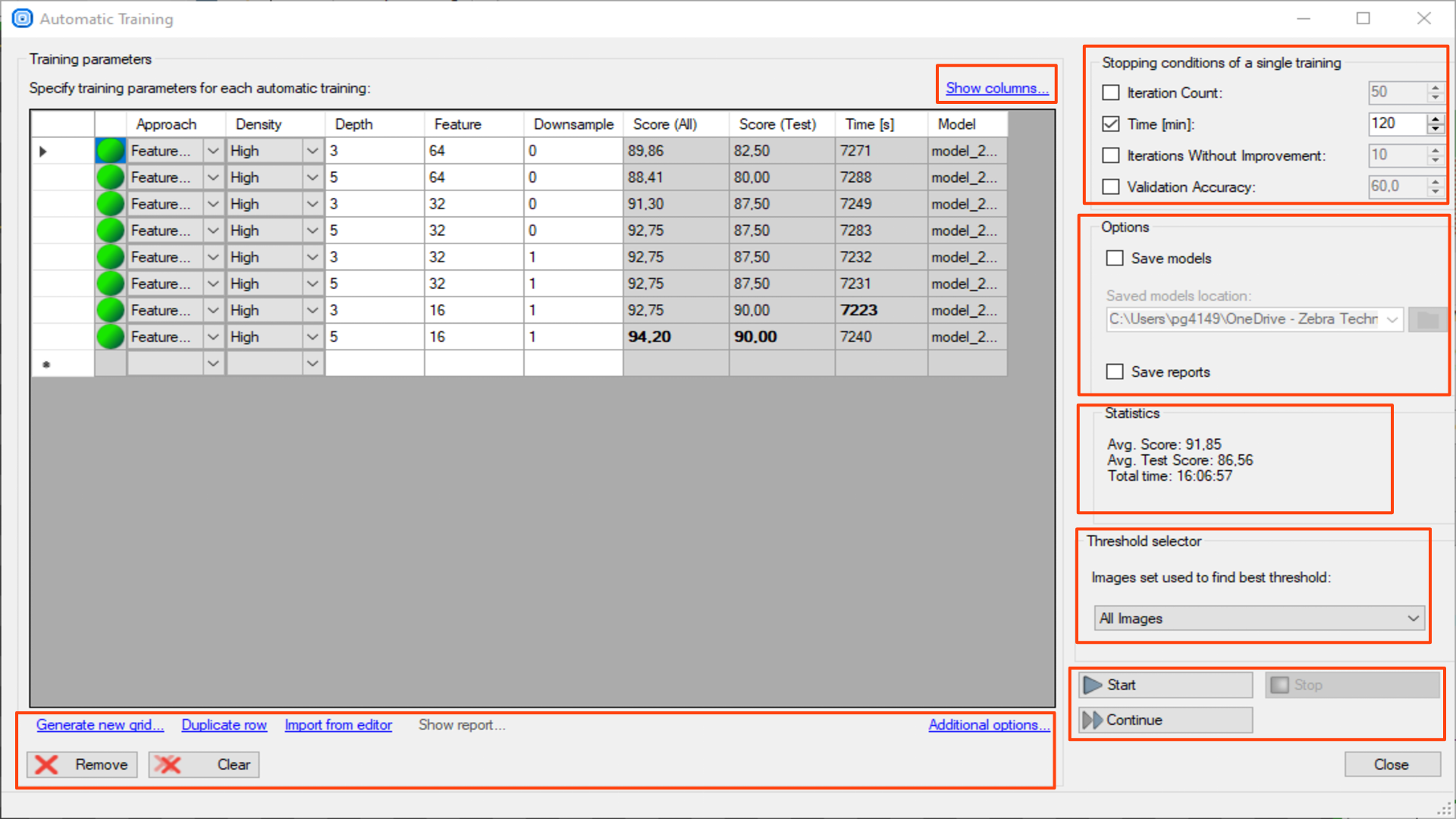
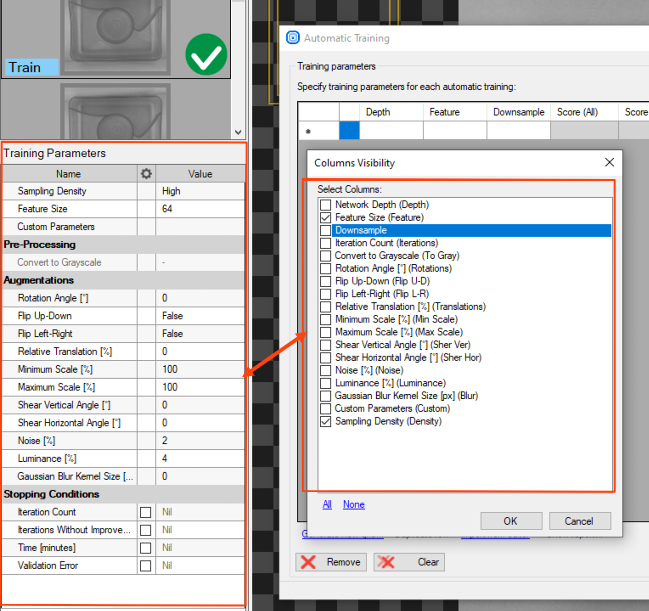
列を表示 – テストで使用するモデルパラメータを表示または非表示にします。
このビューはすべての深層学習ツールに共通です。 適切なグリッド検索を作成するには、使用するツールに適したこれらのパラメーター (トレーニング パラメーターで確認できるパラメーター) を選択します。 DL_DetectAnomalies2 の場合は、最初にネットワーク タイプを選択して、適切なパラメータを表示します。
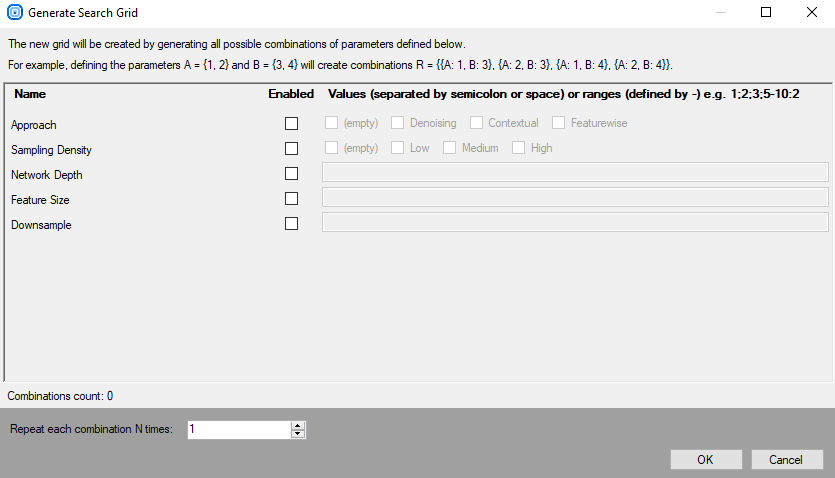
新しいグリッドを生成 – 指定されたパラメータの検索グリッドを準備します。 [列の表示] で選択したパラメータのみが使用可能です。 値は ; 記号で区切る必要があります。
行が重複しています – トレーニングパラメータ設定を複製します。 行内のパラメータが変更されない場合、このモデルは 2 回トレーニングされます。
エディタからインポート – トレーニング パラメータをエディタ ウィンドウから検索グリッドの最後の行にコピーします。
レポートを表示 – は、選択したモデル (選択した行) のレポートを示します。 このオプションは、トレーニング セッションを開始する前にレポートの保存を選択した場合にのみ使用できます。
追加オプション
- グリッドを CSV ファイルにエクスポート – トレーニング パラメータのグリッドを CSV ファイルにエクスポートします。
- CSV ファイルからグリッドをインポートします – CSV ファイルからトレーニング パラメータのグリッドをインポートします。
削除 – 選択したトレーニング構成を削除します。
クリア – 検索グリッド全体をクリアします。
単一トレーニングの停止条件 – 単一のトレーニングがいつ停止されるかを決定します。
- 反復回数
- 時間
- 改善のない反復
- 検証の精度
オプション
- モデルを保存 – トレーニングされた各モデルを定義されたフォルダーに保存します。
- レポートを保存 – モデルの保存用に定義されたフォルダーに、トレーニング済みモデルごとのレポートを保存します。
統計 – すべてのトレーニングの統計を示します。
- 平均 スコア – すべての画像のすべてのトレーニング済みモデルの平均スコアを示します。
- 平均 テストスコア – テスト画像のトレーニングされたすべてのモデルの平均スコアを示します。
- 合計時間 – 各トレーニングの時間を合計します。
しきい値セレクター – どの画像グループに対して最適なしきい値が検索されるかを選択します。
- すべての画像
- テスト画像
開始 – 最初に定義された構成でトレーニング シリーズを開始します。
停止 – トレーニング シリーズを停止します。
続行 – 停止したトレーニング シリーズをパラメータの次の構成で継続します。
異常の検出 1
このツールでは、ユーザーはどの画像に正しいケース (良い) が含まれるか、または間違ったケース (悪い) が含まれるかをマークするだけで済みます。
1. 良いサンプルと悪いサンプルをマークし、それらをテスト データとトレーニング データに分割します。
疑問符記号をクリックすると、トレーニング セット内の各画像に良いまたは悪いというラベルが付けられます。 トレーニング画像の右側にある緑と赤のアイコンは、画像がどのセットに属しているかを示します。
または、画像とマークを追加... を使用することもできます。 次に、画像の左側のラベルをクリックして、画像をトレーニングまたはテストに分割します。 不良サンプルはすべてテストとしてマークする必要があることに注意してください。
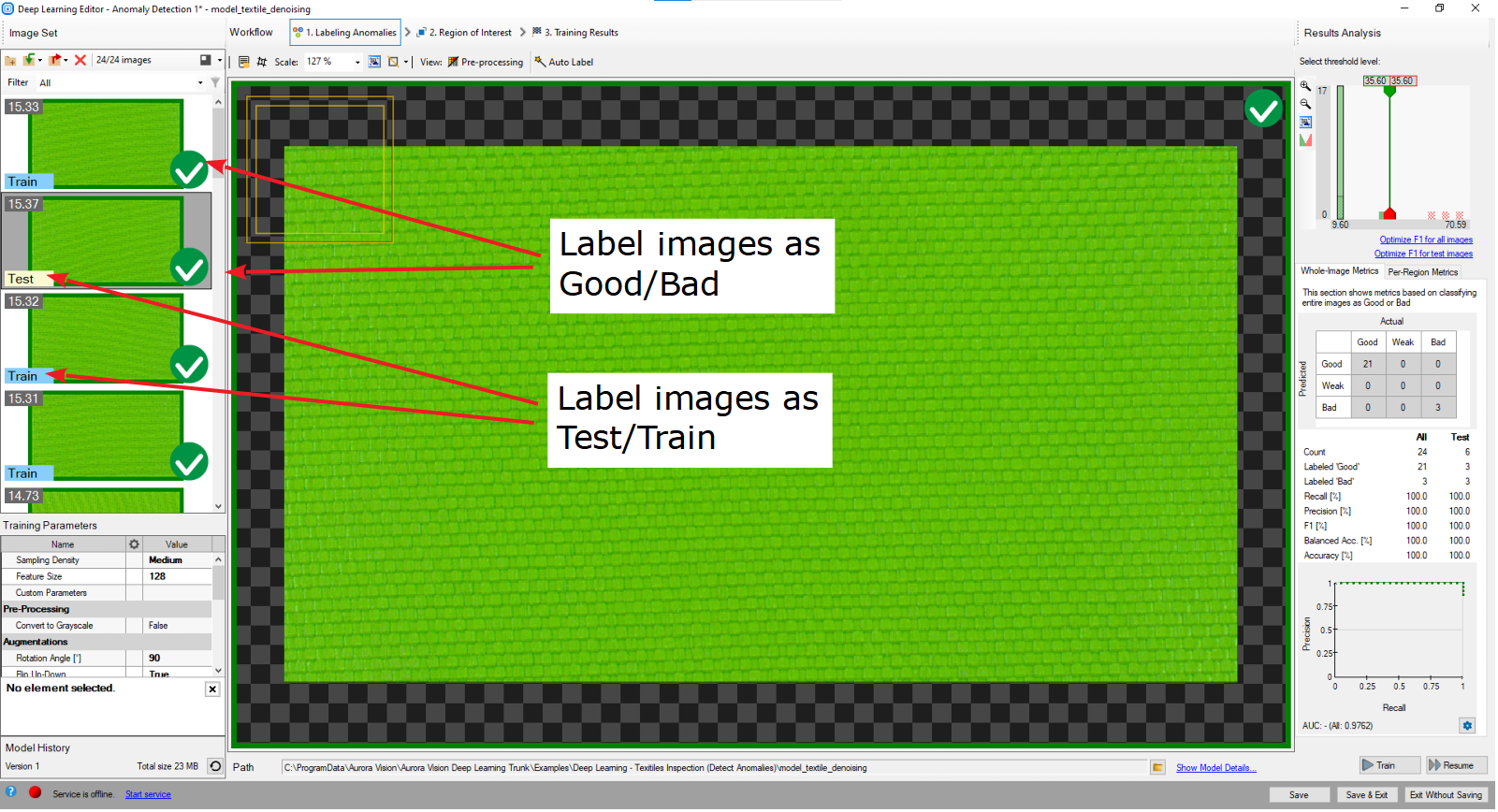
Deep Learning Editor でのラベル付き画像
2. オーグメンテーションの構成
通常、特にトレーニング セットが小さい場合は、サンプルの拡張をいくつか追加することをお勧めします。 たとえば、ユーザーはピクセル強度のバリエーションを追加して、生産ラインのさまざまな照明条件に合わせてモデルを準備できます。 深層学習 - 拡張パラメータの詳細な説明については、「拡張」セクションを参照してください。
3. 関心領域の縮小
対象領域を縮小して、画像の重要な部分のみに焦点を当てます。 関心領域を減らすと、トレーニングと推論の両方が高速化されます。
このツールの関心領域はトレーニング セット内の各画像で同じであり、個別に調整できないことに注意してください。 その結果、この関心領域はモデルの実行中に自動的に適用されるため、ユーザーはプログラム エディターでのサイズや形状に影響を与えません。
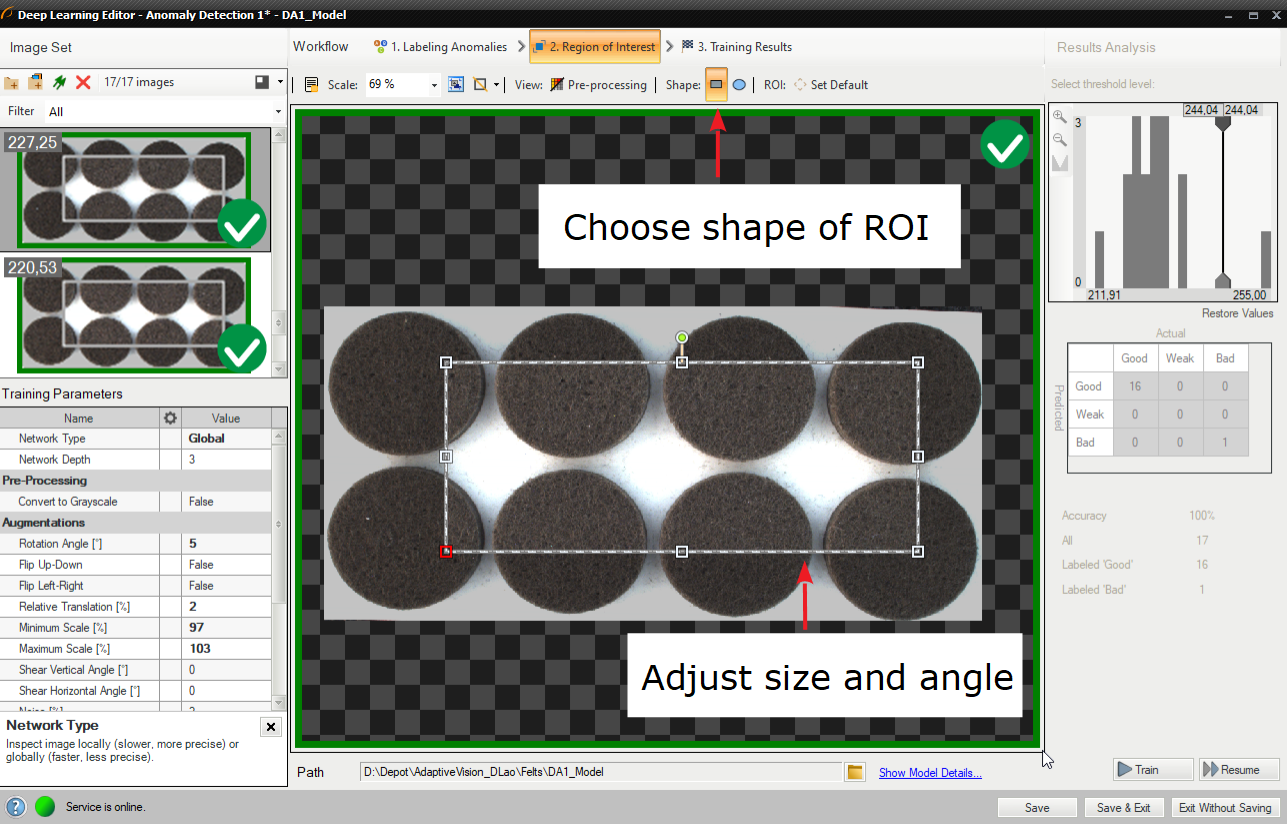
デフォルトでは、対象領域には画像全体が含まれます。
4. トレーニングパラメータの設定
- サンプリング密度 (DL_DetectAnomalies1 および DL_DetectAnomalies2 のみ) の Featurewise アプローチの場合 – 低、中、高から選択します。
- 特徴サイズ (ローカル タイプのみ) – 検査ウィンドウの幅。 エディタの左上隅にある小さな四角形で、選択したフィーチャのサイズが視覚化されます。
- 停止条件 – トレーニング プロセスをいつ停止するかを定義します。
詳細については Deep Learning – Setting parametersをご覧ください。
5. トレーニングの実施
トレーニング中、トレーニング エラーと検証エラーの 2 つの数値が連続して表示されます。 両方のグラフに同様のパターンがあるはずです。
より詳細な情報は、以下のグラフに表示されます。
- 現在のトレーニング統計 (トレーニングと検証)、
- 処理されたサンプルの数 (画像の数と特徴のサイズによって異なります)、
- 経過時間。
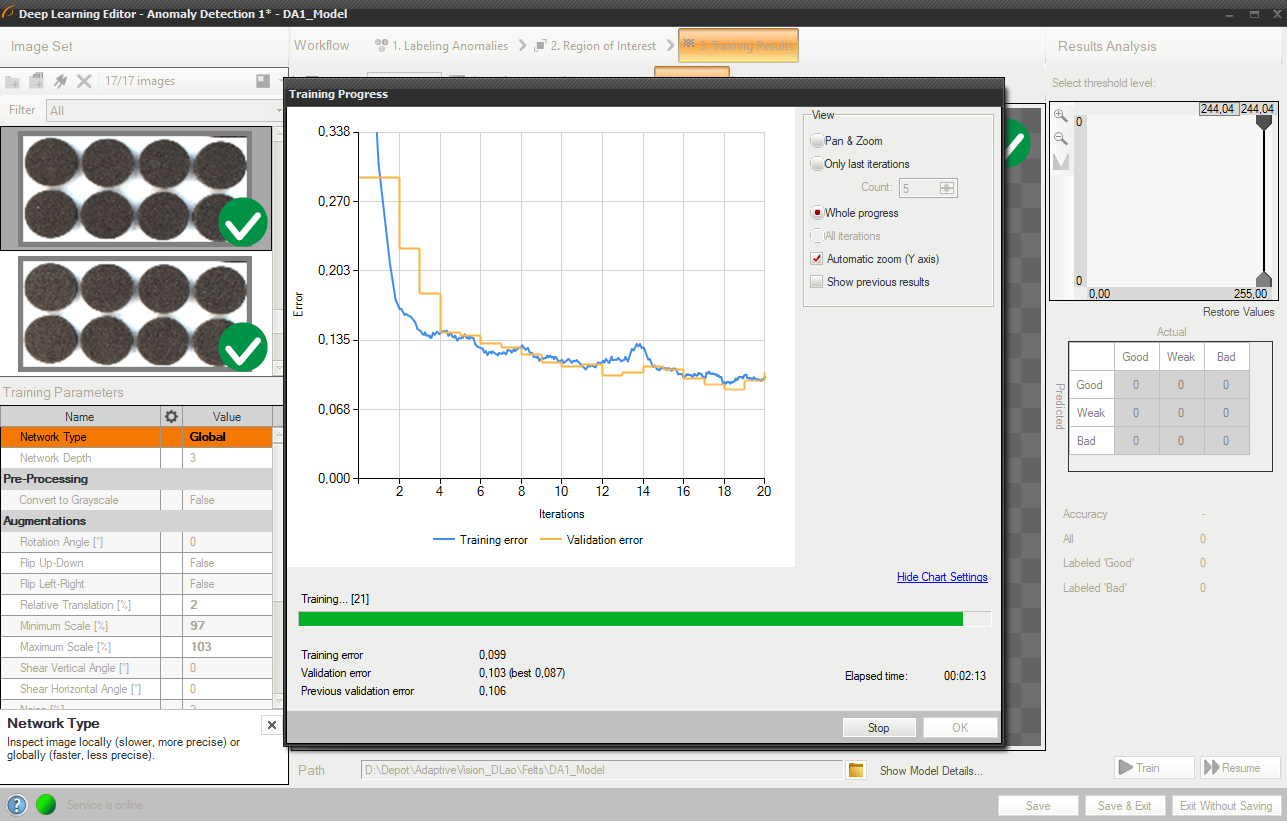
トレーニング プロセスは、トレーニング エラーと検証エラーの計算で構成されます
選択した停止基準と利用可能なハードウェアによっては、トレーニング プロセスに時間がかかる場合があります。 この間、「停止」ボタンをクリックすることで、いつでもトレーニングを手動で終了できます。 モデルが存在しない場合 (最初のトレーニング試行)、検証精度が最も高いモデルが保存されます。 トレーニングを継続的に試行すると、ユーザーに古いモデルの交換についてのメッセージが表示されます。
6. 結果の分析
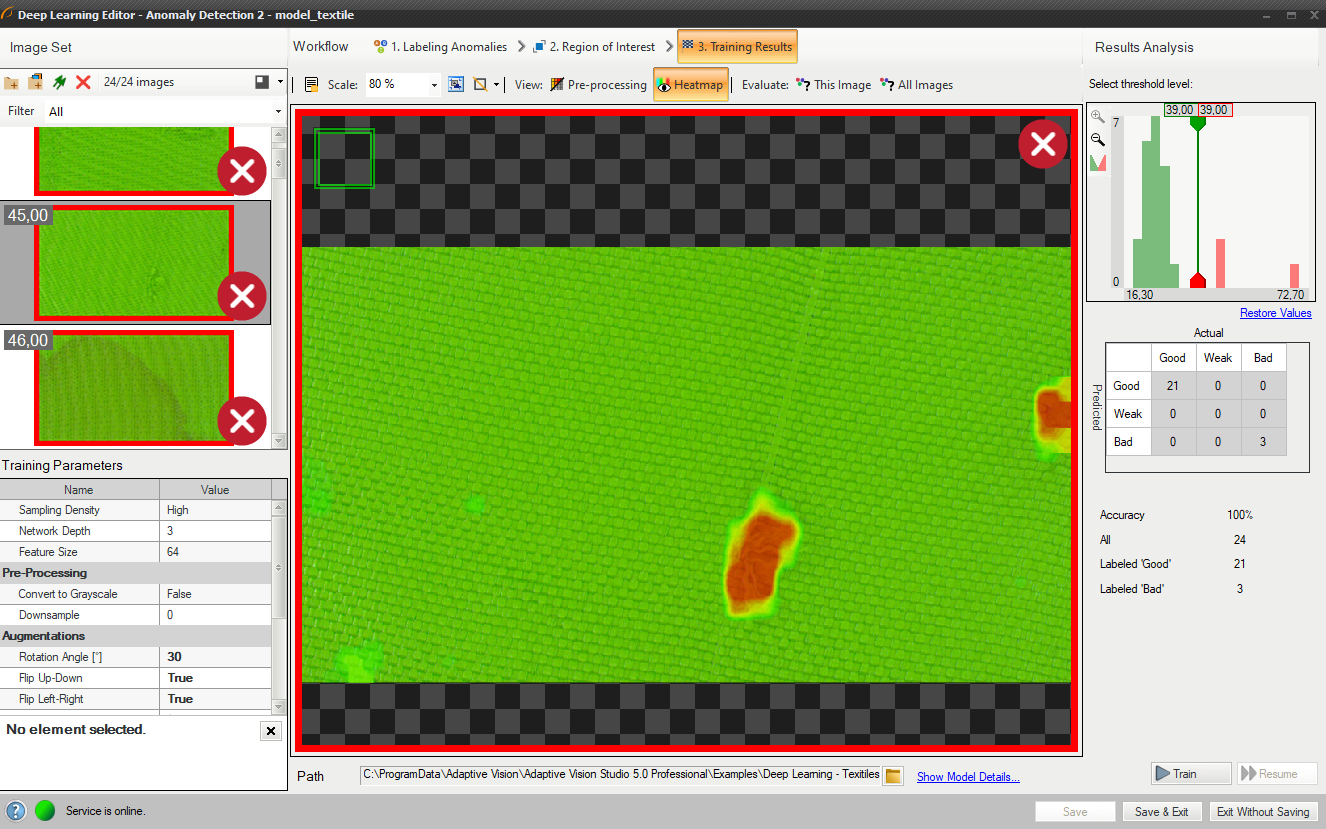
ウィンドウには、サンプル スコアのヒストグラムと見つかった欠陥のヒートマップが表示されます。 左側の列には、トレーニング セット内の各画像に対して計算されたスコアのヒストグラムが含まれています。 追加の統計はヒストグラムの下に表示されます。
トレーニングされたモデルを評価するには、評価: この画像 または 評価: すべての画像 ボタンを使用できます。 新しい画像をデータセットに追加した後、または対象領域を変更した後に役立ちます。
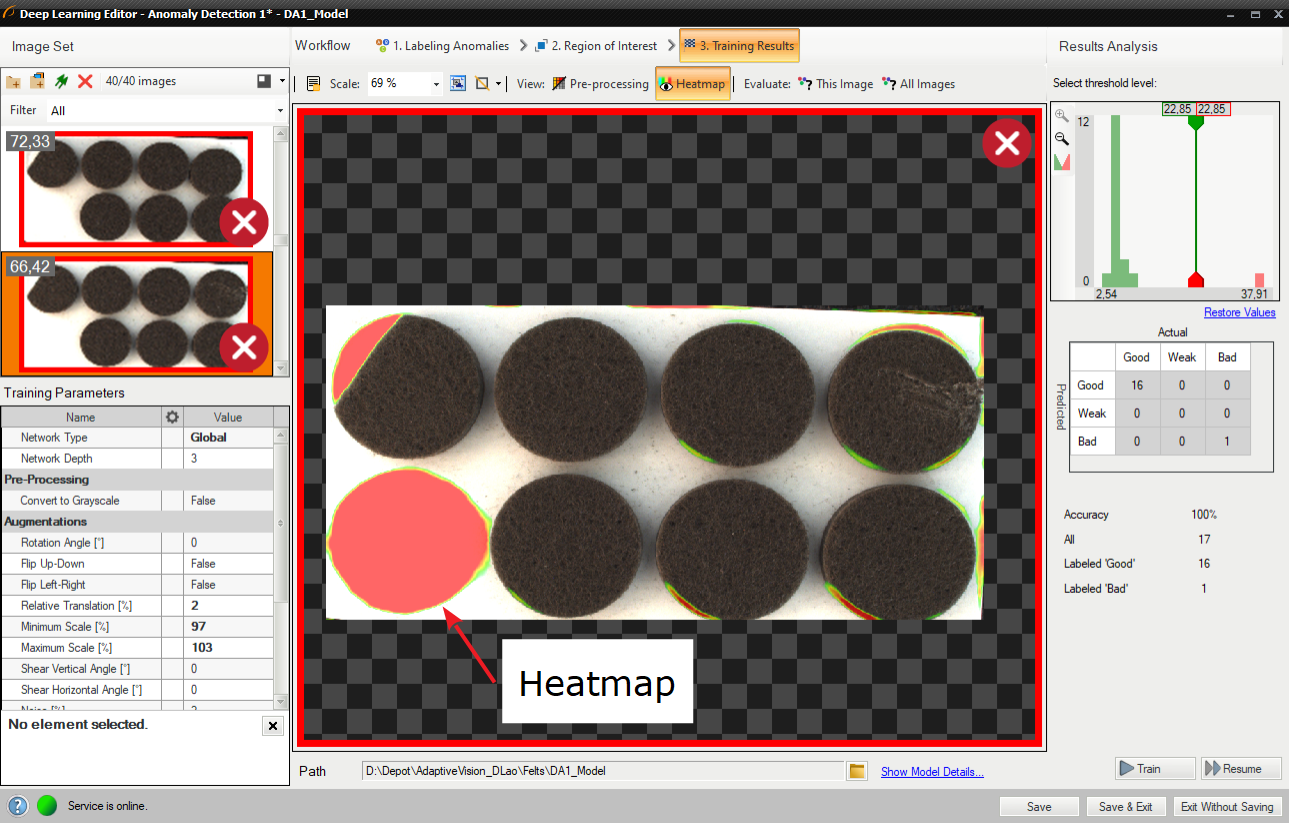
ヒートマップには、欠陥の可能性がある領域が表示されます
トレーニング後、2 つの境界値が計算されます。
- 最大良好サンプル スコア (T1) – 0 から T1 までのすべての値が Good としてマークされます。
- 最小不良サンプル スコア (T2) – T2 より大きい値はすべて Bad としてマークされます。
T1 と T2 の間のすべてのスコアは「低品質」としてマークされます。 この範囲での結果は不確実であり、正しくない可能性があります。 フィルタには、T1 ~ T2 の範囲にない値を決定する追加の出力 outIsConfident が含まれています。
評価後、トレーニング画像のリストで追加のフィルタリング オプションを使用できます。
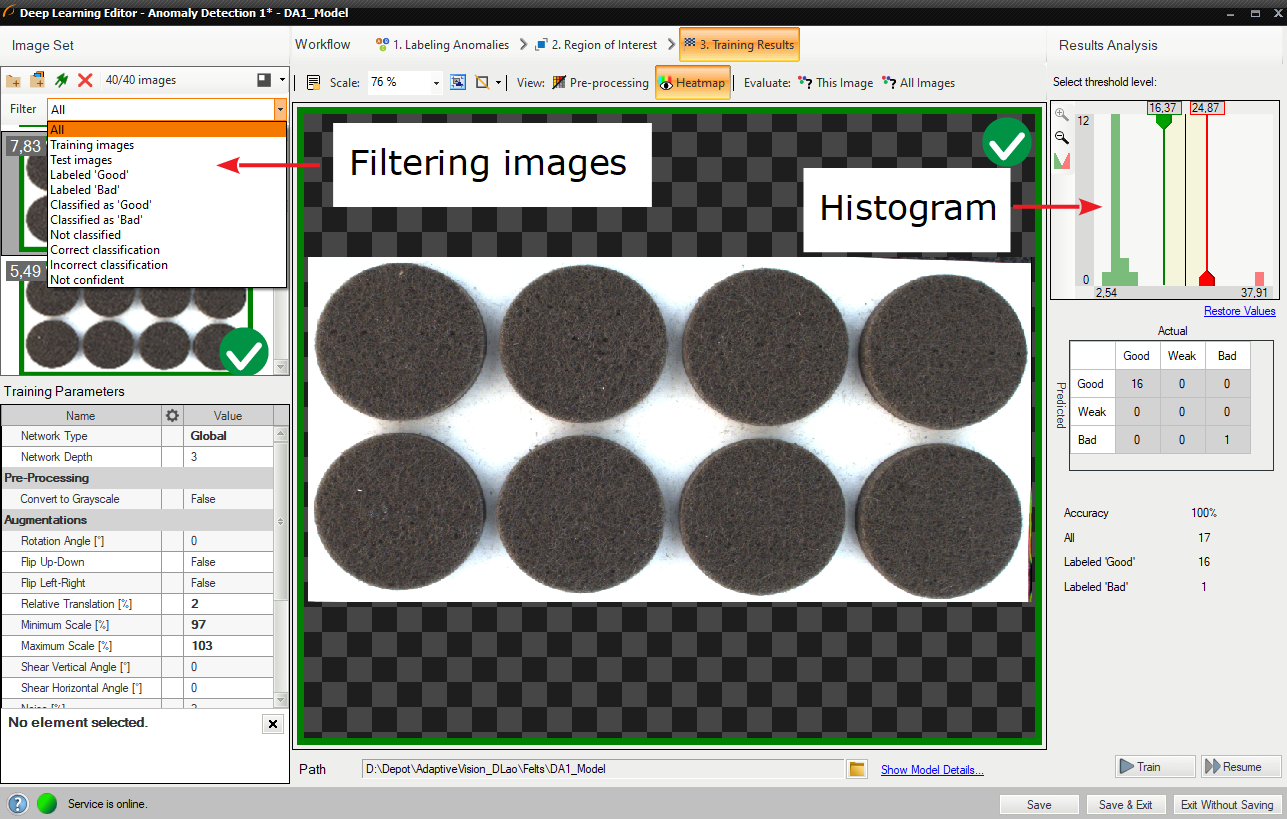
トレーニング セット内の画像をフィルタリングします。
インタラクティブなヒストグラム ツール
DetectAnomalies フィルターは、トレーニング段階で学習した通常の画像の外観からのサンプルの偏差を測定します。 偏差が所定のしきい値を超える場合、画像は異常としてマークされます。 推奨されるしきい値はトレーニング フェーズ後に自動的に計算されますが、ユーザーがディープ ラーニング エディターで後述の対話型ヒストグラム ツールを使用して調整することもできます。
トレーニング フェーズの後、トレーニング サンプルごとにスコアが計算され、ヒストグラムの形式で表示されます。 良好なサンプルは緑色のバーでマークされ、不良サンプルは赤色のバーでマークされます。 完璧なケースでは、良好なサンプルのスコアは不良サンプルのスコアよりもすべて低くなり、モデルの精度が最適になるようにしきい値が自動的に計算されるはずです。 ただし、次の理由により、グループが重複する場合があります。
- サンプルのラベルが間違っている
- 不正な 特徴サイズ
- 予想される欠陥の定義があいまい
- サンプルの外観や環境条件のばらつきが大きい
より堅牢なしきい値を達成するには、両方のグループからの多数のサンプルを使用してトレーニングを実行することをお勧めします。 サンプル数が制限されている場合、当社のソフトウェアを使用すると、追加のしきい値を使用して不確実性領域を手動で設定できます (モデルの信頼性に関する情報は、非表示の outIsConfident フィルター出力から取得できます)。
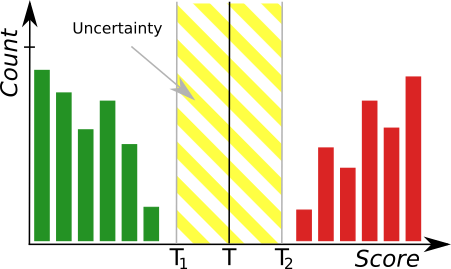
ヒストグラム ツール。緑色のバーは正しいサンプルを表し、赤色のバーは異常なサンプルを表します。 T は主なしきい値を示し、T1、T2 は不確実性の領域を定義します。
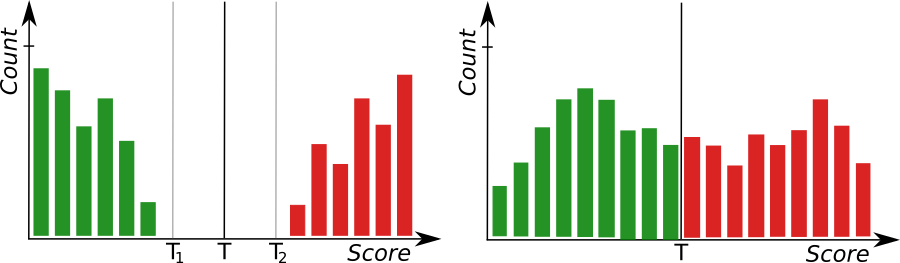
左: モデルの精度が良好であることを示す、十分に分離されたグループを示すヒストグラム。 右: モデルの精度が低い。
異常の検出 2 (分類的アプローチ)
DL_DetectAnomalies2 は、異常の検出に使用できる別のフィルターです。 これは同じ問題を別の方法で解決するように設計されています。 画像再構成技術を使用する代わりに、Anomaly Detection 2 は入力画像の各部分の 1 クラス分類を実行します。
どちらのツールも非常に似ているため、モデルを作成する手順は同じです。 モデル パラメーター セクションのこれらのフィルター間の違いはわずかです。 DL_DetectAnomalies2 の場合、ユーザーは反復回数とネットワーク タイプを変更する必要はありません。 代わりに、検査ウィンドウを使用して分析のステップを定義するサンプリング密度を設定することができます。 サンプリング密度が高いほど、ヒートマップはより正確になりますが、トレーニングと推論にかかる時間は長くなります。
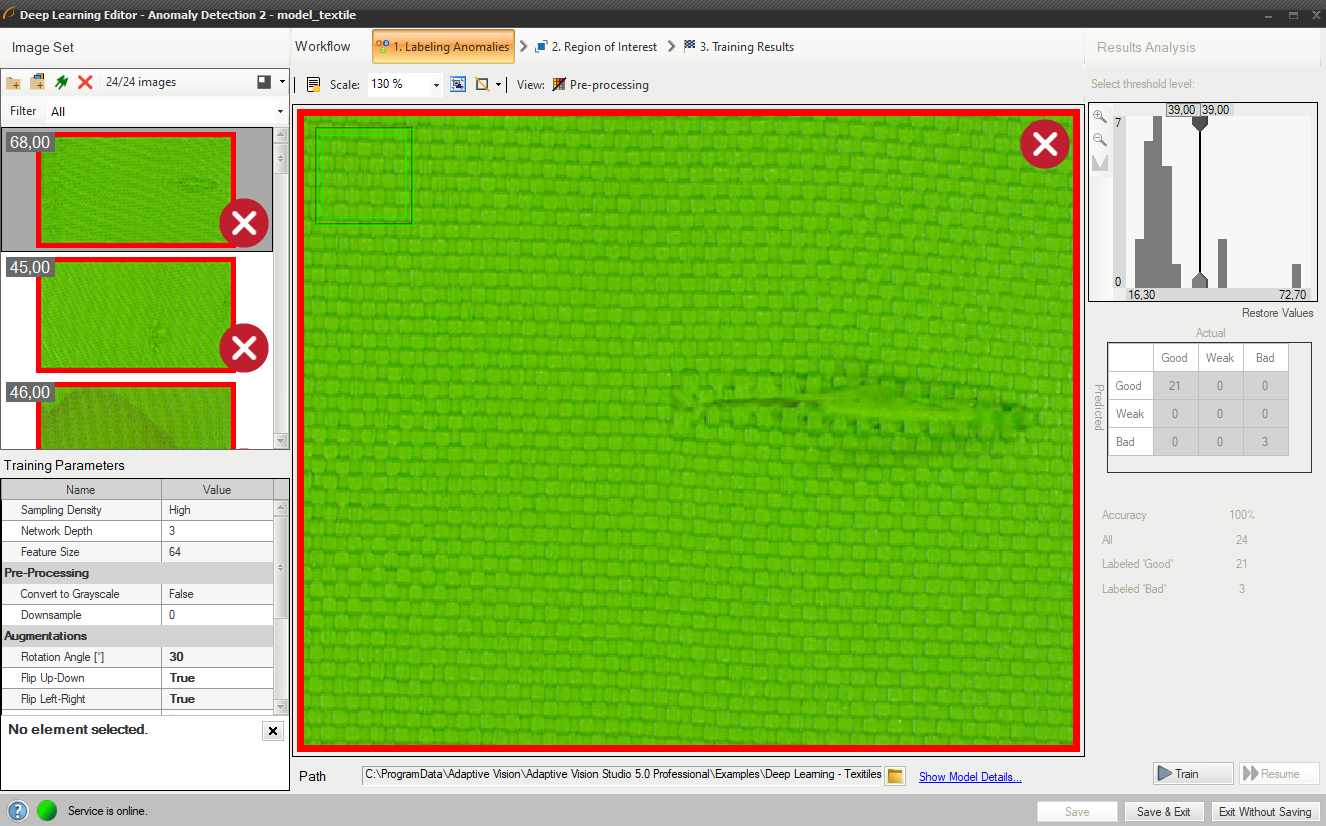
結果は、緑 (良好として分類) または赤 (不良として分類) の 2 色の長方形としてマークされます。
結果として得られるヒートマップは、通常、再構成的異常検出を使用した場合ほど空間的には正確ではありませんが、スコアの精度とヒストグラム上のグループ分離ははるかに優れている可能性があります。
ヒートマップは、欠陥の可能性が最も高い位置を示します
特徴の検出 (セグメンテーション)
このツールでは、ユーザーは各フィーチャクラスを定義し、トレーニング セット内の各画像上のフィーチャをマークする必要があります。 この技術は、傷や色の変化などのオブジェクトの欠陥を見つけたり、選択したパターンでトレーニングされた画像部分を検出したりするために使用されます。
1. フィーチャクラスの定義 (マーキングクラス)
まず、ユーザーは欠陥のクラスを定義する必要があります。 一般に、それらはユーザーが画像上で検出したい特徴である必要があります。 複数の異なるクラスを定義できますが、複数のクラスを使用することはお勧めできません。
クラス エディタは、上部バーのスプロケット ホイール アイコンの下で利用できます。
クラスを管理するには、Add, Remove or Rename を使うことができます。 外観をカスタマイズするには、色の変更ボタンを使用して各クラスの色を変更できます。
このツールでは、より多くのクラスの欠陥を定義できます。
編集対象の現在のクラスが左側に表示され、ユーザーはクリック後に別のクラスを選択できます。
描画ツールを使用して、入力画像上の特徴をマークします。 ブラシや長方形などのツールは、フィーチャの選択に使用できます。
さらに、クラス マスクを外部ファイルからインポートできます。 作成されたクラスの インポート と エクスポート のボタンがあるため、ユーザーは深層学習モデルの前にマスクのイメージを自動的に作成できます。
画像マスクは、入力セットで選択された画像と同じサイズである必要があります。 画像マスクをインポートすると、黒以外のピクセルがすべて現在のマスクに含まれます。
ツールの最も重要な機能。
ユーザーは、[画像とマスクを追加] ボタンを使用して、複数の画像とマスクを同時に読み込むこともできます。
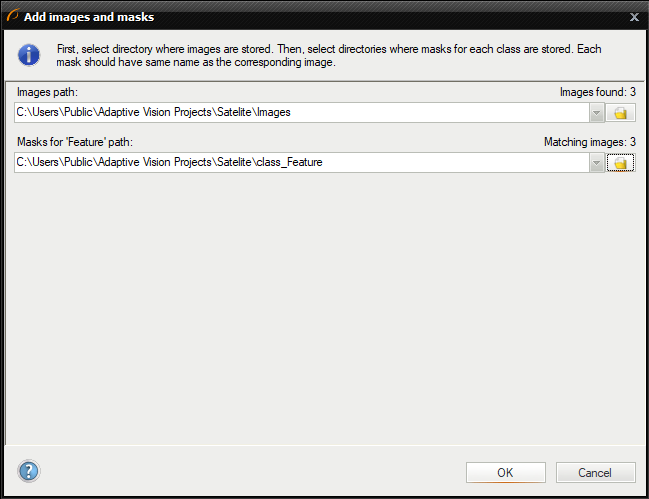
画像とマスクへのパスを選択
入力画像を含むディレクトリを最初に選択する必要があります。 次に、各フィーチャクラスのディレクトリを以下で選択できます。 画像とマスクは、ファイル名を使用して自動的に照合されます。 たとえば、「images」ディレクトリに画像 001.png、002.png、003.png が含まれているとします。 「mask_class1」ディレクトリには 001.png、002.png、003.png が含まれています。 「mask_class2」ディレクトリには 001.png、002.png、003.png が含まれます。 次に、「images\001.png」イメージが「mask_class1\001.png」および「mask_class2\001.png」マスクとともにロードされます。
2. 関心領域の縮小
ユーザーは入力画像のサイズを小さくして、トレーニング プロセスを高速化できます。 多くの場合、画像上の特徴の数は非常に多く、そのほとんどは同じです。 このような場合、対象領域を縮小することもできます。
上部のバーには、現在の ROI をすべての画像に適用したり、ROI をリセットしたりするためのツールがあります。
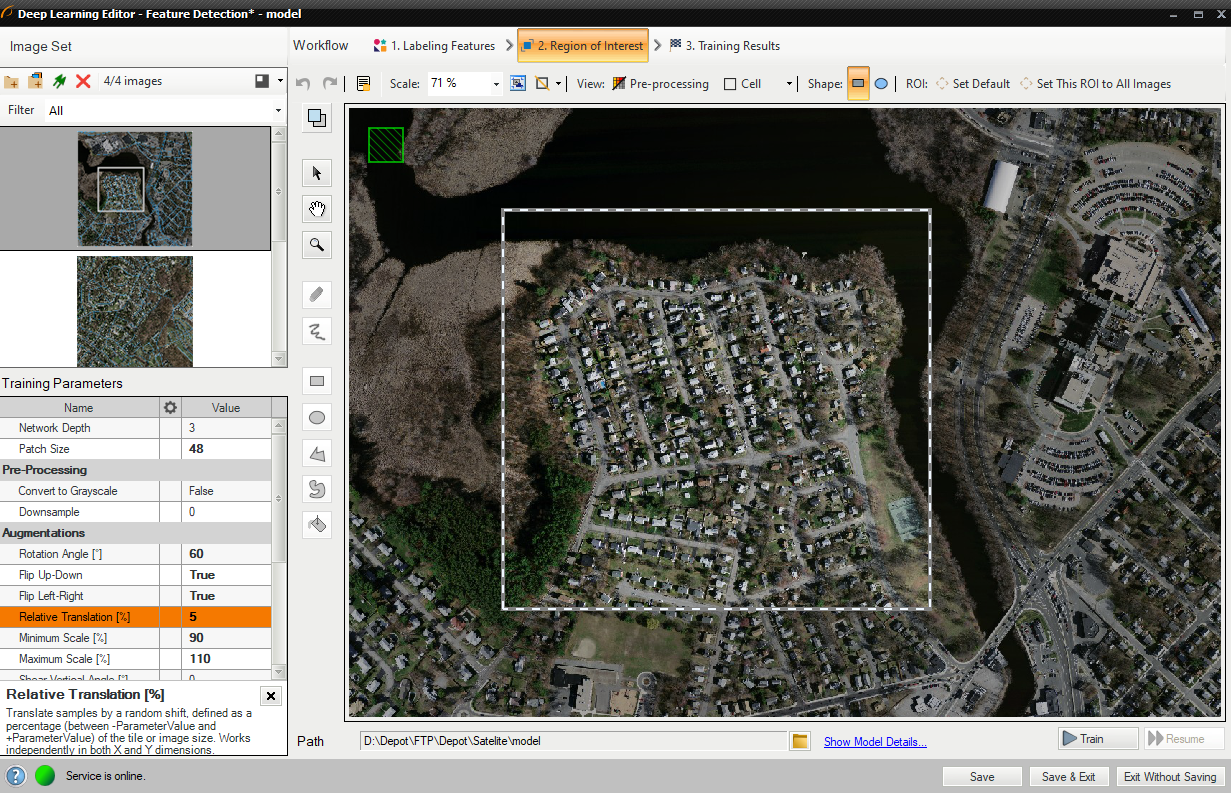
ROIの設定
3. トレーニングパラメータの設定
- ネットワークの深さ – 複雑さの異なるいくつかの事前定義されたネットワーク アーキテクチャの 1 つを選択します。 より大きく複雑な画像パターンの場合は、より深い深度が必要になる場合があります。
- パッチ サイズ – ニューラル ネットワークの 1 回のパスで分析される画像部分のサイズ。 これは対象となるどの特徴よりも大幅に大きい必要がありますが、大きすぎないように注意してください。 パッチのサイズが大きくなるほど、トレーニング プロセスは難しくなり、時間がかかります。
- 停止条件 – トレーニング プロセスをいつ停止するかを定義します。
詳細については、 Deep Learning – Setting parameters and Deep Learning – Augmentationを参照してください。
4. モデルのトレーニング
グラフには、トレーニング スコアと検証スコアという 2 つのシリーズが含まれています。 スコア値が高いほど、より良い結果が得られます。
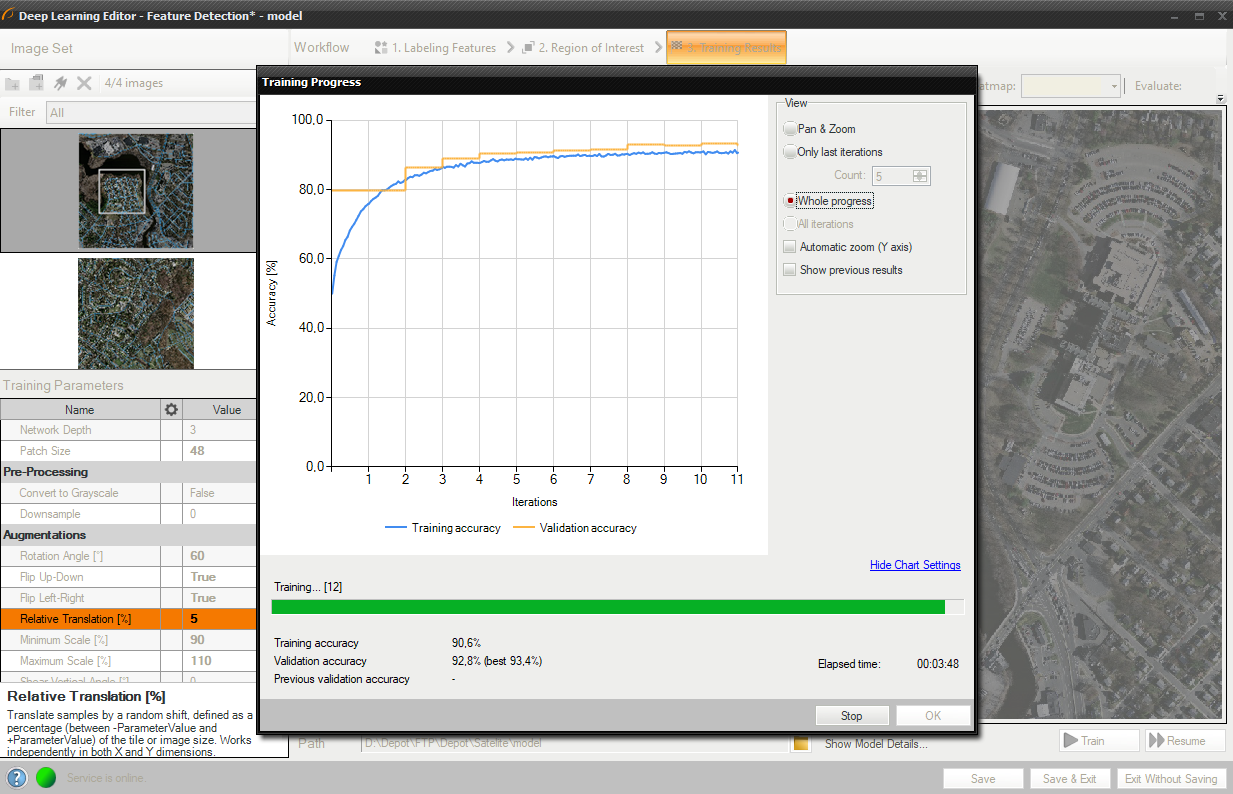
この場合、トレーニング プロセスは、トレーニングと検証の精度を計算することで構成されます。
5. 結果分析
画像スコア (ヒートマップ) は、モデルを使用して画像を評価した後、青、黄、赤のカラー パレットで表示されます。 色は、現在選択されているフィーチャクラスに要素が属する確率を表します。
評価: この画像 ボタンと評価: すべての画像 ボタンを使用して画像を分類できます。 新しい画像をデータセットに追加した後、または対象領域を変更した後に役立ちます。
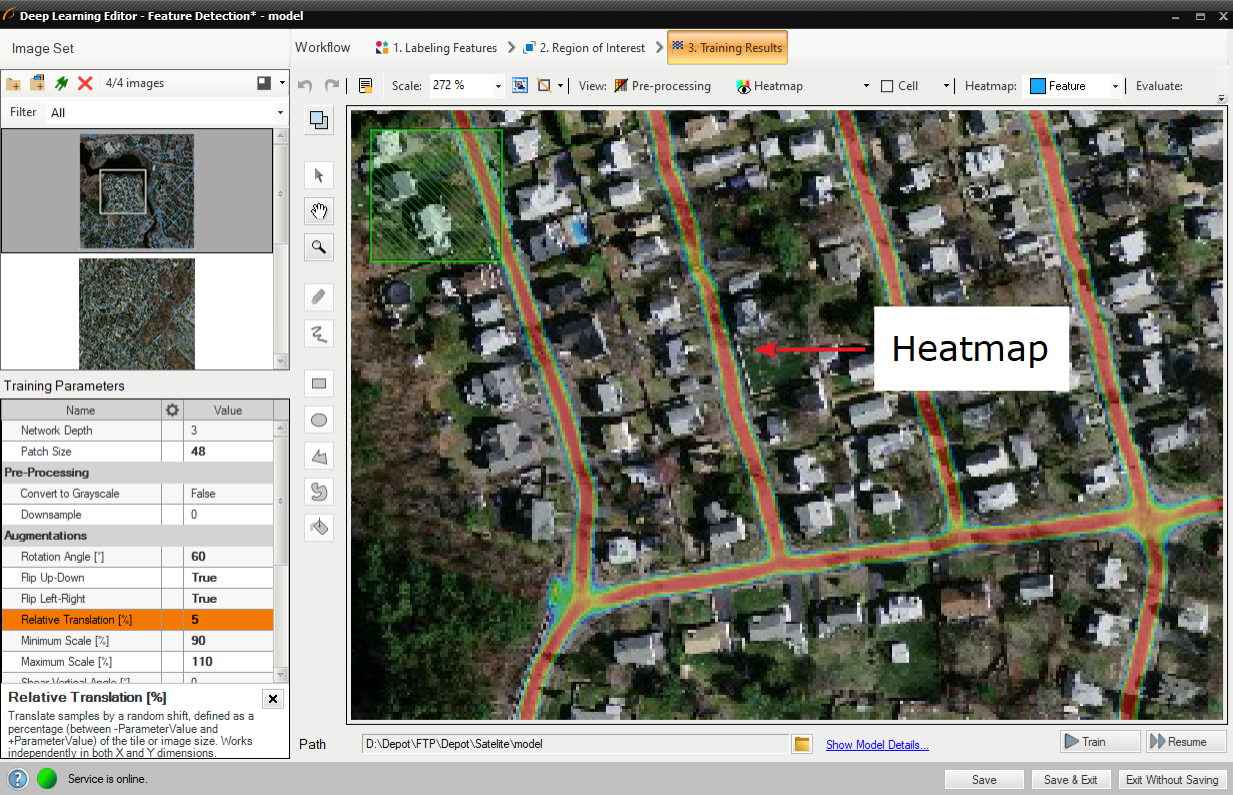
分類後の画像
エディタの左上隅にある緑色の四角形は、選択したパッチ サイズを視覚化します。
オブジェクトの分類
この場合も、ユーザーは必要な数のクラスに関して画像にラベルを付けるだけで済みます。 理論的には、ユーザーが作成できるクラスの数は無限ですが、GPU が処理できるデータ量によって制限されることに注意してください。 ラベル付き画像を使用すると、モデルをトレーニングし、新しいサンプルを評価して適切なクラスに割り当てるために使用される特徴を決定できます。
1. クラス数の編集
デフォルトでは 2 つのクラスが定義されています。 問題がそれよりも複雑な場合は、ユーザーはクラスを編集し、必要に応じてさらに定義することができます。 ユーザーがクラスを定義する準備ができたら、画像にラベルを付けることができます。
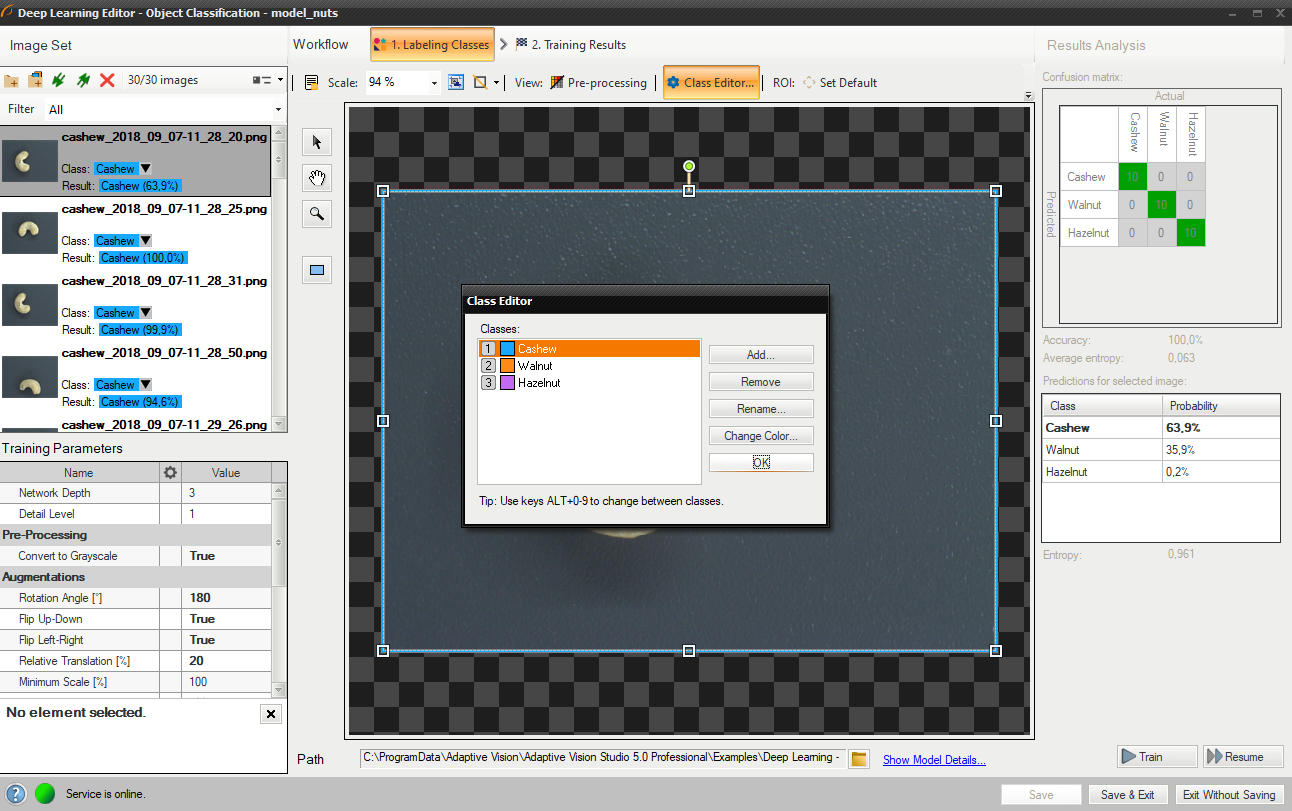
クラス エディターの使用
2. ラベルサンプル
トレーニング画像を追加した後、サンプルのラベル付けが可能です。 各イメージには、特定のクラスを割り当てることができる対応するドロップダウン リストがあります。 Deep Learning Editor で目的の画像を選択することで、1 つのクラスを複数の画像に割り当てることができます。
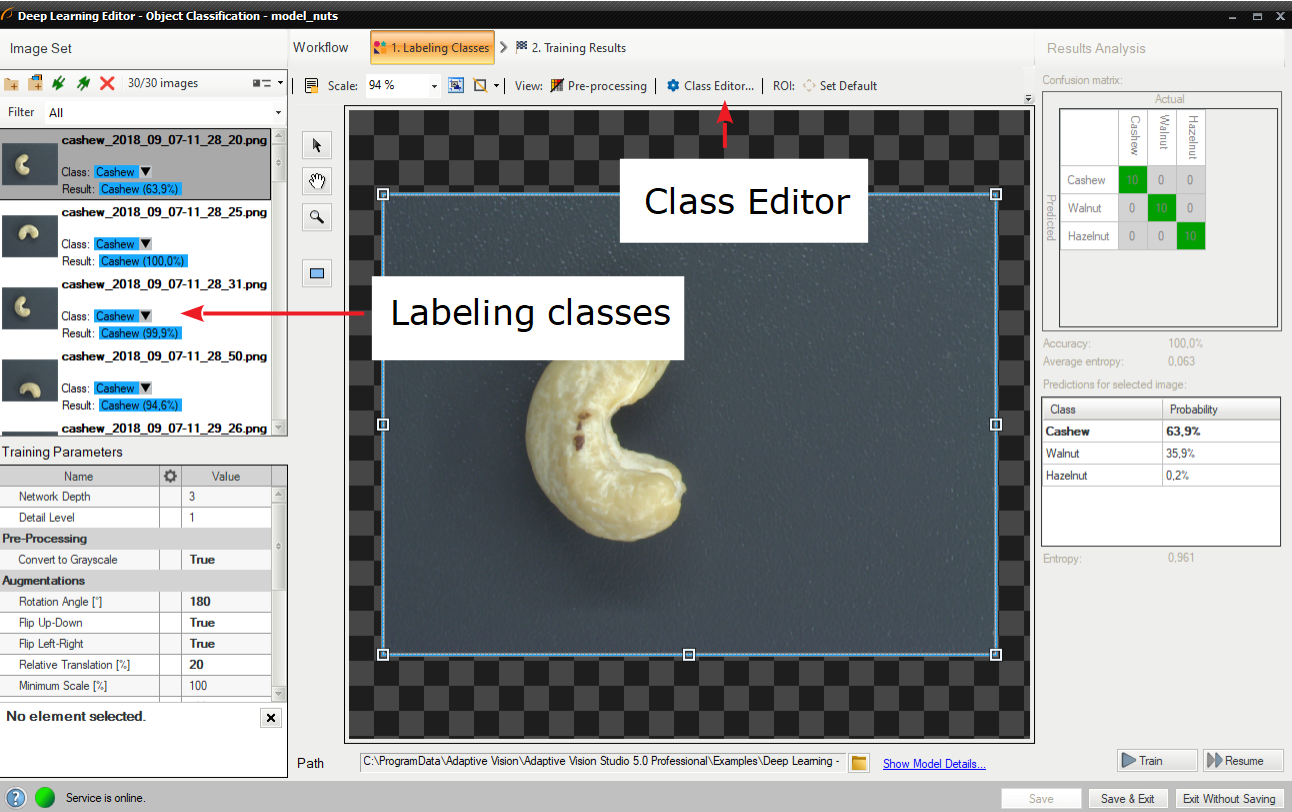
クラスを使用した画像のラベル付け
3. 関心領域の縮小
対象領域を縮小して、画像の重要な部分のみに焦点を当てます。 関心領域を減らすと、トレーニングと分類の両方が高速化されます。 デフォルトでは、対象領域には画像全体が含まれます。
最良の分類結果を得るには、トレーニングと分類に同じ関心領域を使用します。
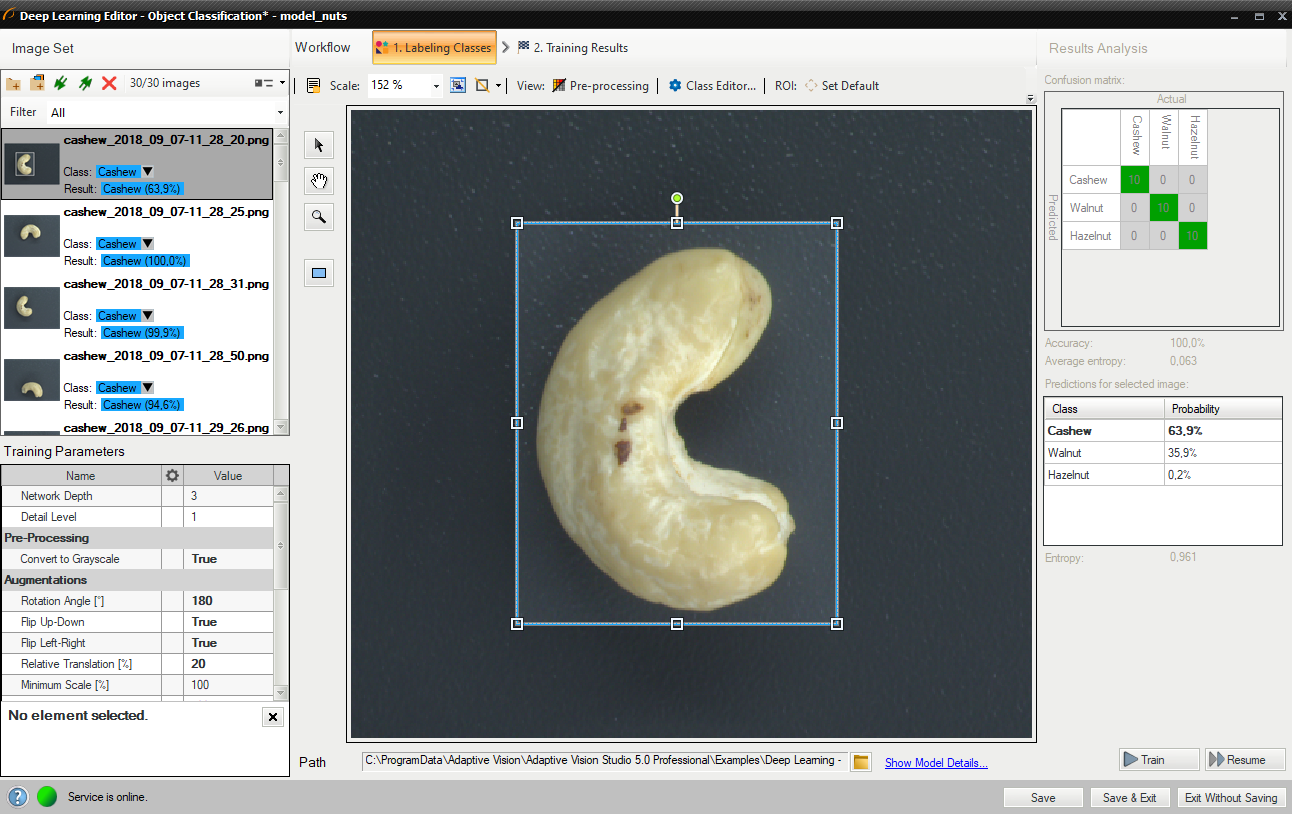
変更された関心領域
4. トレーニングパラメータの設定
- ネットワークの深さ – 事前定義されたネットワーク アーキテクチャ パラメータ。 より複雑な問題の場合は、さらに深いレベルが必要になる場合があります。
- 詳細レベル – 特定の分類タスクに必要な詳細レベル。 ほとんどの場合、デフォルト値の 1 が適切ですが、異なるクラスの画像が小さな特徴によってのみ区別できる場合は、このパラメータの値を増やすと分類結果が改善される可能性があります。
- 停止条件 – トレーニング プロセスをいつ停止するかを定義します。
詳細はDeep Learning – Setting parameters と Deep Learning – Augmentationを参照ください。
5. トレーニングの実行
トレーニング中に、トレーニング精度と検証精度という 2 つの系列が表示されます。 両方のグラフに同様のパターンがあるはずです。
より詳細な情報がグラフの下に表示されます。
- 現在のトレーニング統計 (トレーニングと検証の精度)
- 処理されたサンプルの数 (画像の数によって異なります)
- 経過時間。
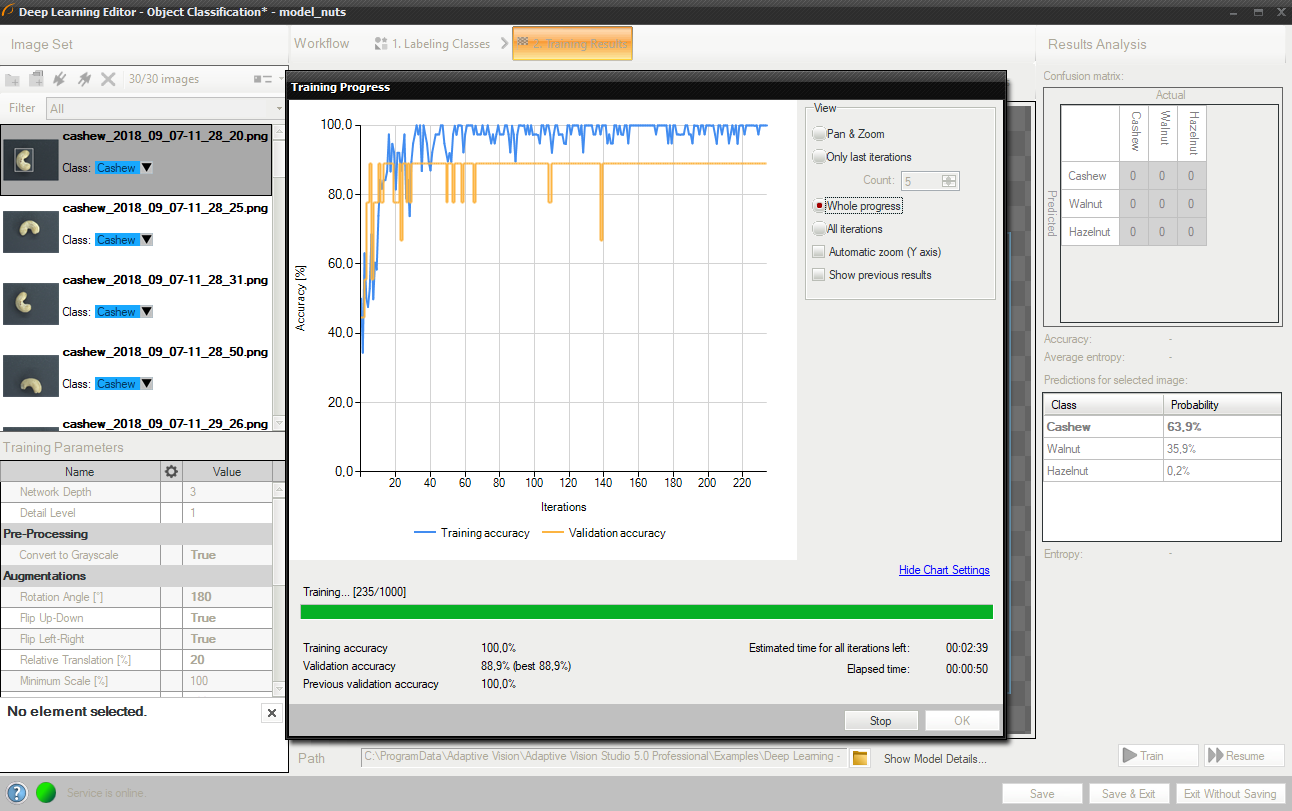
トレーニング オブジェクト分類モデル
トレーニング プロセスには数分またはそれ以上かかる場合があります。 必要に応じて手動で終了することもできます。 1 つのトレーニングの最終結果は、最も高い検証精度を達成した部分モデルの 1 つです (必ずしも最後のモデルである必要はありません)。 トレーニングを継続的に試行すると、新しいモデルを保存するか古いモデルを保持するかをユーザーに尋ねるプロンプトが表示されます。
6. 結果の分析
ウィンドウには、トレーニング サンプルがどの程度適切に分類されているかを示す混同行列が表示されます。
画像ビューには、画像のどの部分が分類結果に最も寄与したかを示すヒートマップが含まれています。
評価: この画像 ボタンと評価: すべての画像 ボタンを使用して、トレーニング画像を分類できます。 新しい画像をデータセットに追加した後、または対象領域を変更した後に役立ちます。
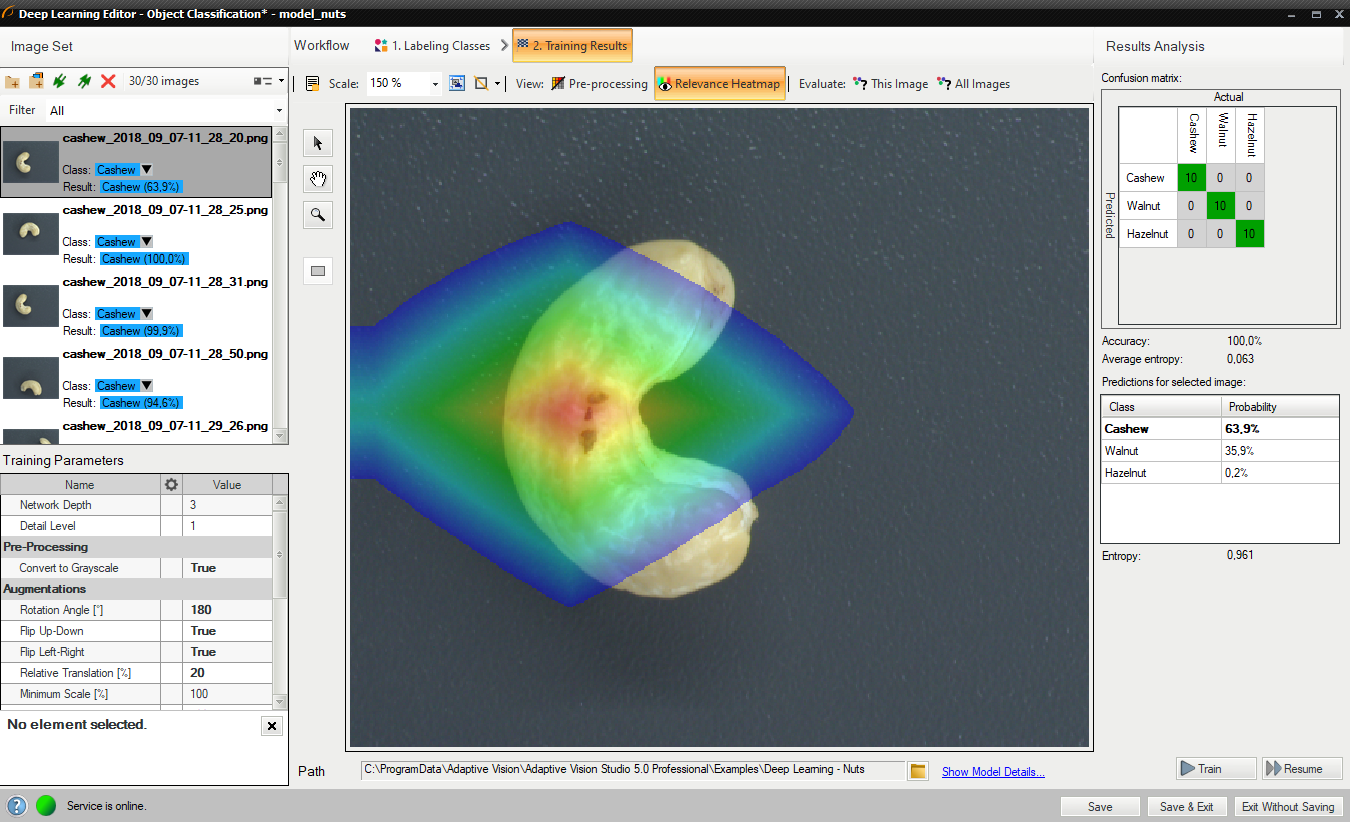
トレーニング後の混乱マトリックスとクラスの割り当て
最初の試行では正しいパラメータを推測するのが難しい場合があります。
下の図は、トレーニング中の不正確な分類を示す混同行列を示しています (左)。

さらなるトレーニングが必要なモデル(左)と十分にトレーニングされたモデル(右)の混同行列。
混同行列は、トレーニングされたモデルがトレーニング サンプルに関して 100% 正確ではないことを示している可能性があります (主対角にのみ割り当てられた数値は 100% の精度を表します)。 ユーザーはこのデータを適切に分析し、有利に使用する必要があります。
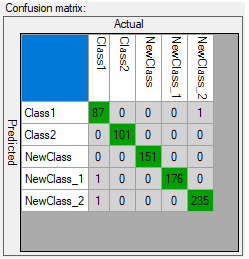
適切な一般化を示す混同行列
誤った分類が多すぎる場合は、トレーニングが不十分であることを示しています。 モデルがトレーニング サンプルとの正確な一致ではなく一般化に適切に焦点を当てていることを示すものはほとんどありません (過剰適合の可能性)。 トレーニングに使用される画像が異なる場合 (単一クラス間であっても)、適切な一般化を達成できます。 提供されたデータがクラス内で変化しておらず (ユーザーは正確な一致を期待しています)、トレーニング後に一部の画像が主対角線の外側に分類されている場合、ユーザーは次のことができます。
- ネットワークの深さを増やす
- 反復回数を増やしてトレーニングを延長する
- トレーニングに使用するデータ量を増やす
- 拡張を使用する
- 詳細レベルのパラメータを増やす
インスタンスのセグメント化
このツールでは、ユーザーはシーン内のオブジェクトに対応する領域 (マスク) を描画し、そのクラスを指定する必要があります。 これらの画像とマスクはモデルをトレーニングするために使用され、モデルは入力画像内のオブジェクトの位置を特定、セグメント化、分類するために使用されます。
1. オブジェクト クラスの定義
まず、ユーザーは、モデルのトレーニング対象となり、後で検出に使用されるオブジェクトのクラスを定義する必要があります。 インスタンス セグメンテーション モデルは、単一クラスだけでなく複数クラスのオブジェクトも処理できます。
クラス エディターは、[クラス エディター] ボタンの下で使用できます。
クラスを管理するには、[追加]、[削除]、または [名前変更] ボタンを使用できます。 外観をカスタマイズするには、[色の変更] ボタンを使用して各クラスの色を変更できます。
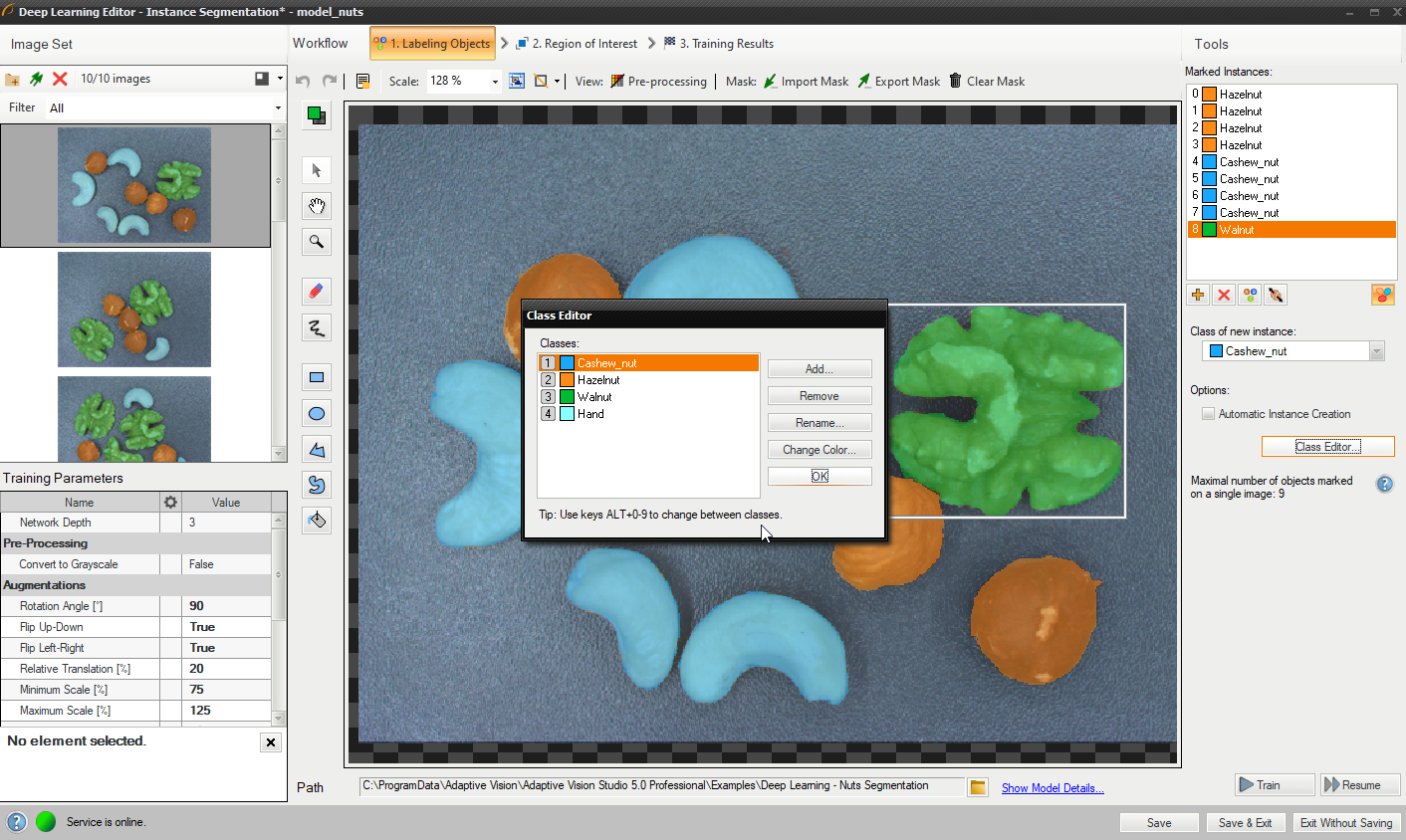
クラス エディタの使用
2. オブジェクトのラベル付け
トレーニング画像を追加してクラスを定義した後、ユーザーは領域 (マスク) を描画して画像内のオブジェクトをマークする必要があります。
オブジェクトをマークするには、[現在のクラス] ドロップダウン メニューで適切なクラスを選択し、[インスタンスの追加] ボタン (緑色のプラス) をクリックする必要があります。 あるいは、ラベル付けの便宜のために、 ユーザーが画像内の複数のオブジェクトにマスクをすばやく描画できるようにする自動インスタンス作成を適用することもできます。 毎回新しいインスタンスを追加します。
描画ツールを使用して、入力画像上のオブジェクトをマークします。 ブラシやシェイプなどの複数のツールを使用してオブジェクト マスクを描画できます。 マスクは、選択したクラスに対して以前に定義したものと同じ色です。
左上隅の「マークされたインスタンス」リストには、現在のイメージに定義されているオブジェクトのリストが表示されます。 オブジェクトに対応するマスクがイメージ内に作成されていない場合、そのオブジェクトは「(空)」としてマークされます。 オブジェクトが選択されると、作図領域のマスクの周囲に境界ボックスが表示されます。 選択したオブジェクトは、クラス ([クラスの変更] ボタン) およびマスク (新しいパーツを描画するか、既存のパーツを消去するだけ) に関して変更できます。 [インスタンスを削除] ボタン (赤い十字) を使用すると、選択したオブジェクトを完全に削除できます。
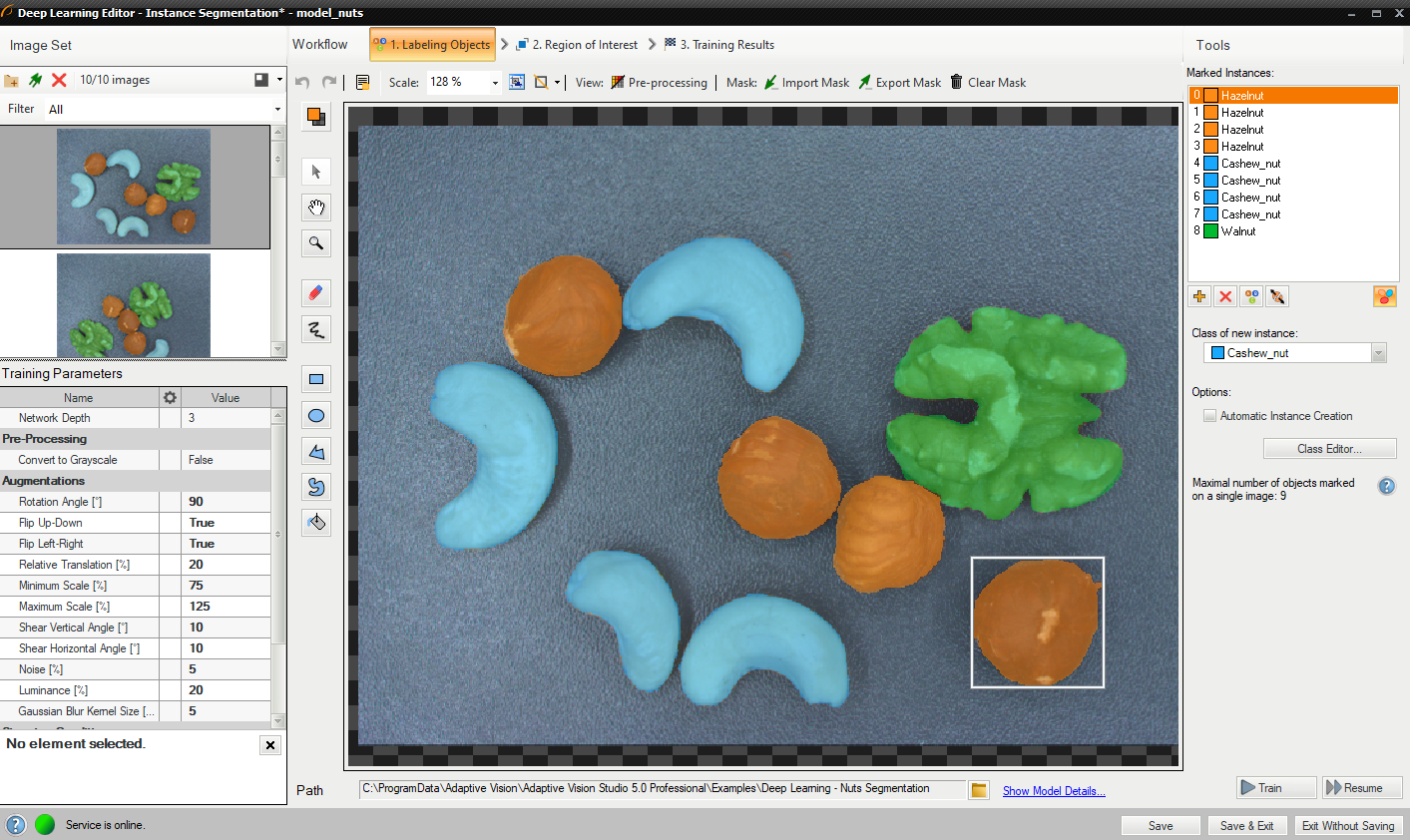
オブジェクトのラベル付け
3. 関心領域の縮小
対象領域を縮小して、画像の重要な部分のみに焦点を当てます。 デフォルトでは、対象領域には画像全体が含まれます。
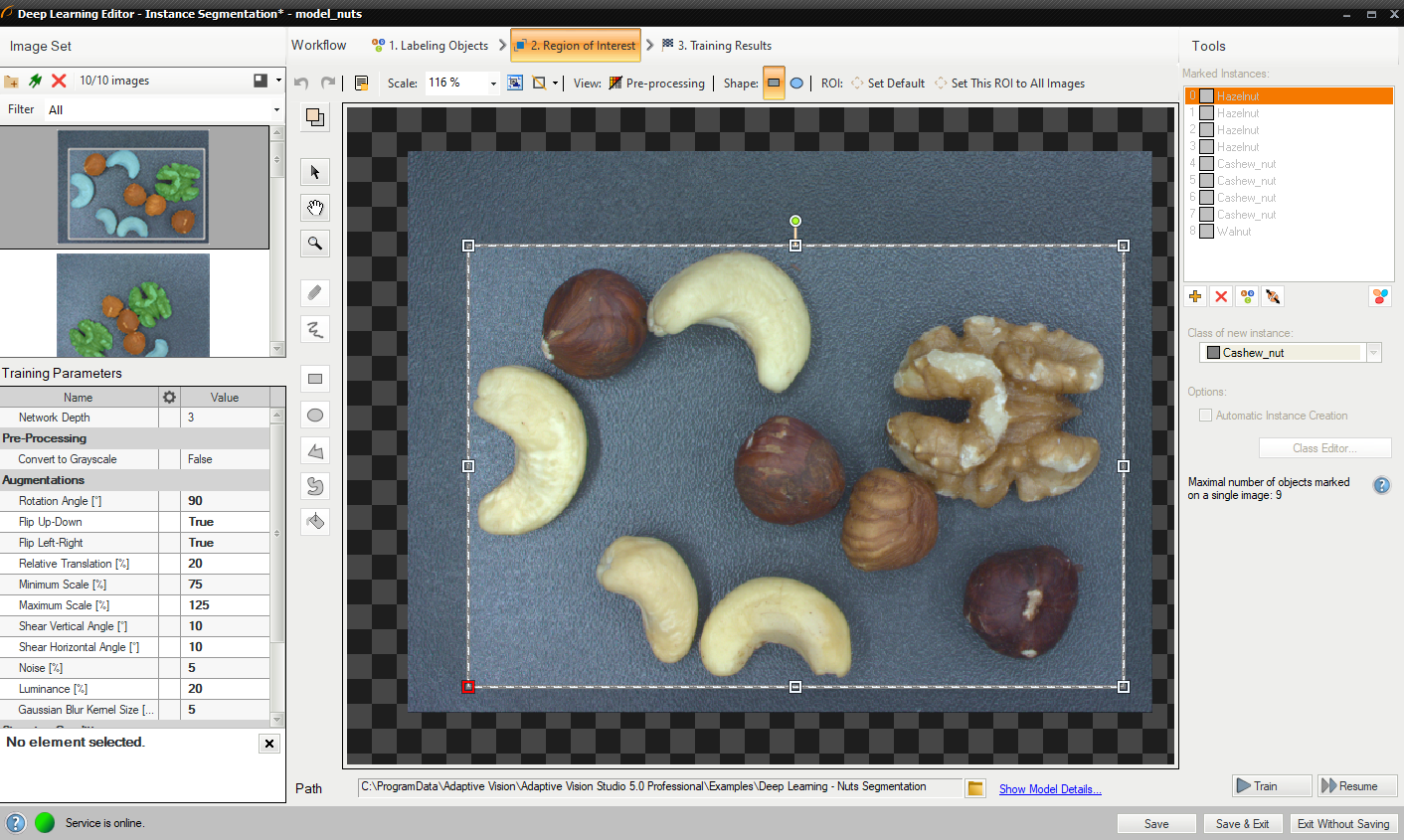
関心領域の変更
4. トレーニングパラメータの設定
- ネットワークの深さ – 事前定義されたネットワーク アーキテクチャ パラメータ。 より複雑な問題の場合は、さらに深いレベルが必要になる場合があります。
- 停止条件 – トレーニング プロセスをいつ停止するかを定義します。
詳細についてはDeep Learning – Setting parameters をご覧ください。。
拡張パラメータに関する詳細: Deep Learning – Augmentation
5. トレーニングの実行
トレーニング中に、トレーニング エラーと検証エラーという 2 つの主要なシリーズが表示されます。 両方のチャートに同様のパターンがあるはずです。 3 番目のシリーズの前にトレーニングが実行された場合、以前の検証エラーも表示されます。
より詳細な情報がグラフの下に表示されます。
- 現在の反復番号
- 現在のトレーニング統計 (トレーニングおよび検証エラー)
- 処理されたサンプルの数
- 経過時間
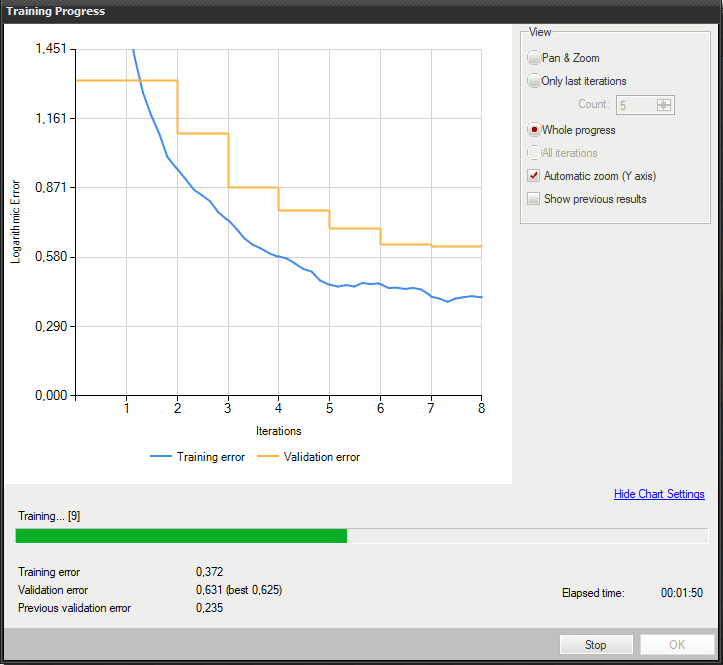
トレーニング インスタンス セグメンテーション モデル
トレーニングは長いプロセスになる場合があります。 この間、トレーニングを停止することができます。 モデルが存在しない場合 (最初のトレーニング試行)、検証精度が最も高いモデルが保存されます。 トレーニングを継続的に試行すると、古いモデルを置き換えるかどうかをユーザーに尋ねるメッセージが表示されます。
6. 結果の分析
ウィンドウにはインスタンスのセグメント化の結果が表示されます。 検出された物体は画像の上に表示されます。 各検出は次のデータで構成されます。
- クラス (色で識別)
- 境界ボックス
- モデル生成のインスタンス マスク
- 信頼スコア
評価: この画像 ボタンと 評価: すべての画像 ボタンを使用して、提供された画像に対してインスタンスのセグメンテーションを実行できます。 新しい画像をデータセットに追加した後、または対象領域を変更した後に役立ちます。
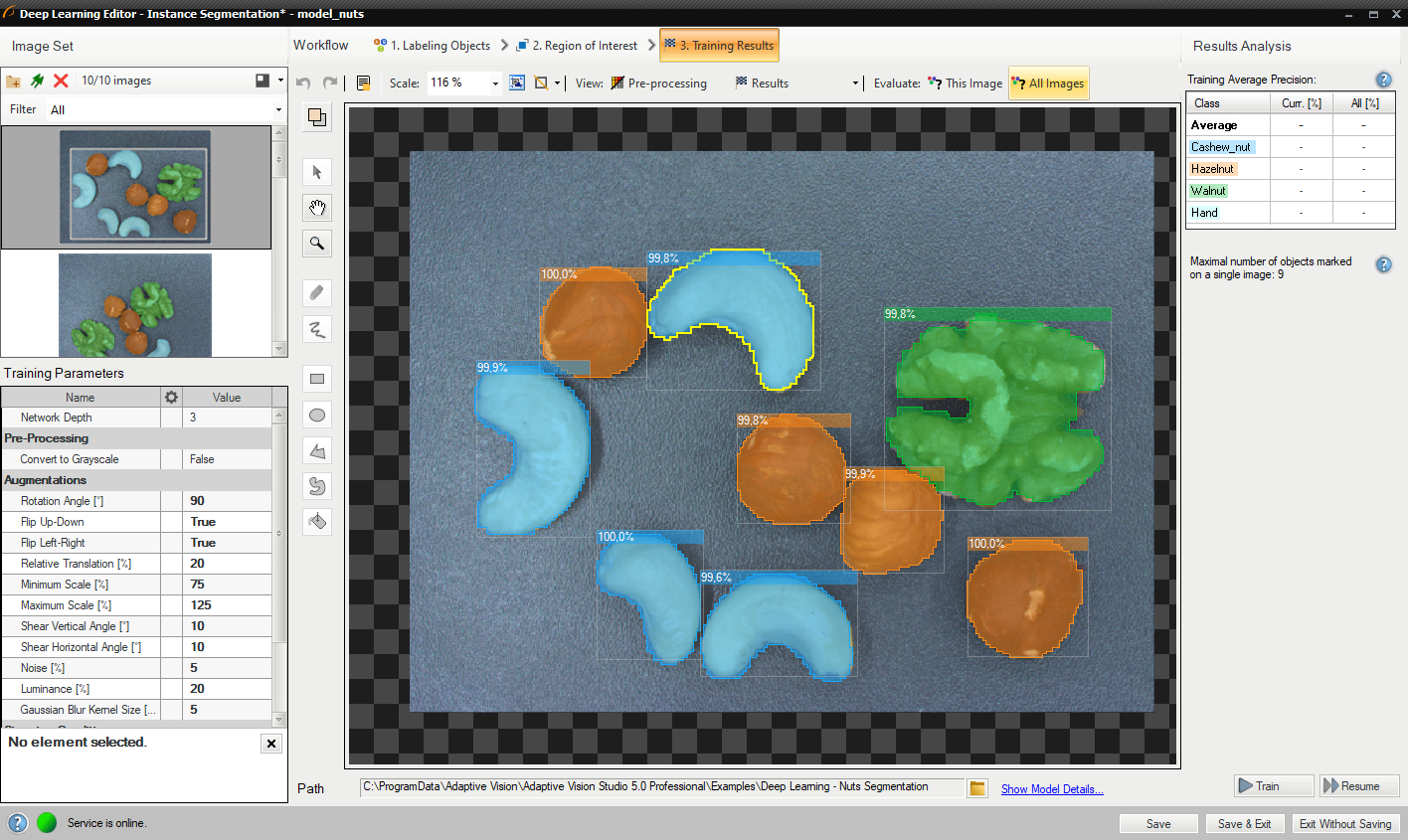
トレーニング後に視覚化されたインスタンスのセグメンテーション結果
インスタンスのセグメンテーションは複雑なタスクであるため、データ拡張を使用して、学習した情報を一般化するネットワークの機能を向上させることを強くお勧めします。 それでも満足のいく結果が得られない場合は、次の標準的な方法を使用してモデルのパフォーマンスを向上させることができます。
- より多くのトレーニング データを提供する
- トレーニングの反復回数を増やす
- ネットワークの深さを増やす
ポイントの特定
このツールでは、ユーザーはクラスを定義し、画像内のキーポイントをマークします。 このデータはモデルをトレーニングするために使用され、その後、画像内のキーポイントを特定して分類するために使用されます。
1. クラスの定義
まず、ユーザーは、モデルがトレーニングされ、後で検出に使用されるキーポイントのクラスを定義する必要があります。 ポイント位置モデルは、単一クラスだけでなく複数クラスのキー ポイントも処理できます。
クラス エディターは、[クラス エディター] ボタンの下で使用できます。
クラスを管理するには、[追加]、[削除]、または [名前変更] ボタンを使用できます。 各クラスの色は、[色の変更] ボタンを使用して変更できます。
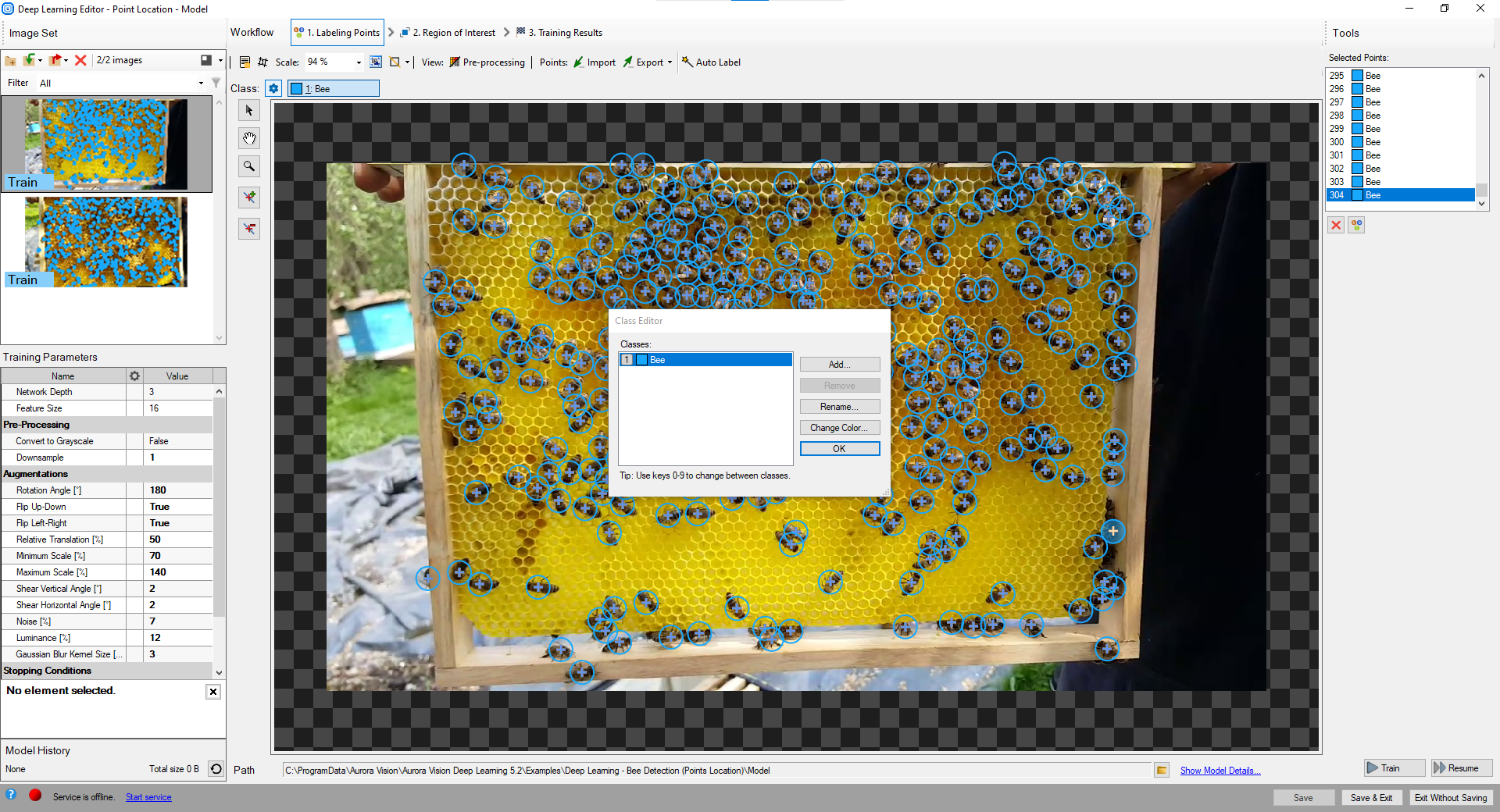
クラスエディタの使用
2. 重要なポイントにマークを付ける
トレーニング画像を追加してクラスを定義した後、ユーザーは画像内のポイントをマークする必要があります。
オブジェクトをマークするには、[現在のクラス] ドロップダウン メニューで適切なクラスを選択し、[ポイントの追加] ボタンをクリックする必要があります。 ポイントの色は、選択したクラスに対して以前に定義したものと同じです。
左上隅の「選択されたポイント」リストには、現在のイメージに定義されたポイントのリストが表示されます。 点はリストから選択することも、画像領域上で直接選択することもできます。 選択したポイントは、移動、削除 ([ポイントの削除] ボタン) するか、クラスを変更する ([クラスの変更] ボタン) ことができます。
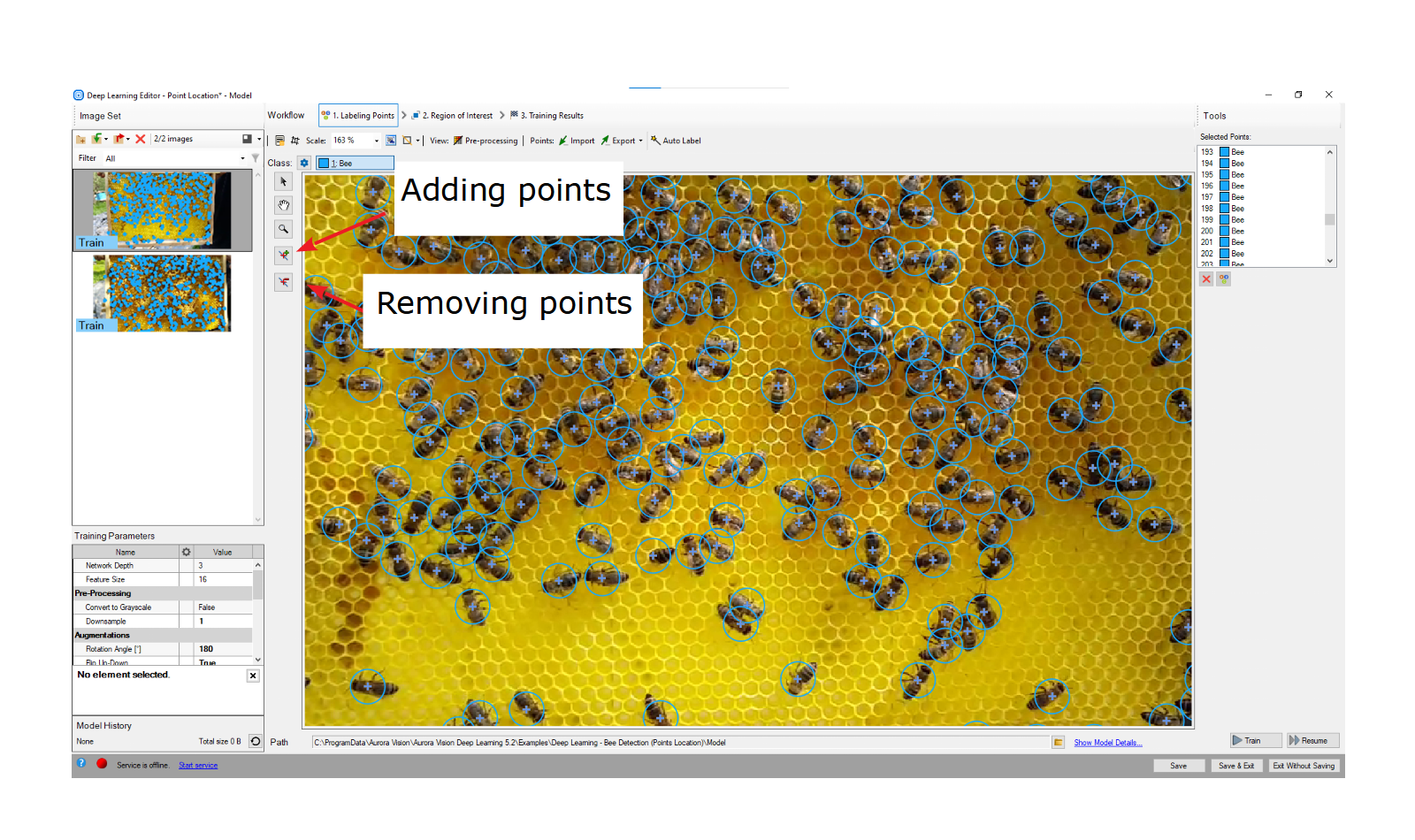
ポイントをマークする
3. 関心領域の縮小
関心領域を縮小して画像の重要な部分のみに焦点を当て、トレーニング プロセスを高速化します。 デフォルトでは、対象領域には画像全体が含まれます。
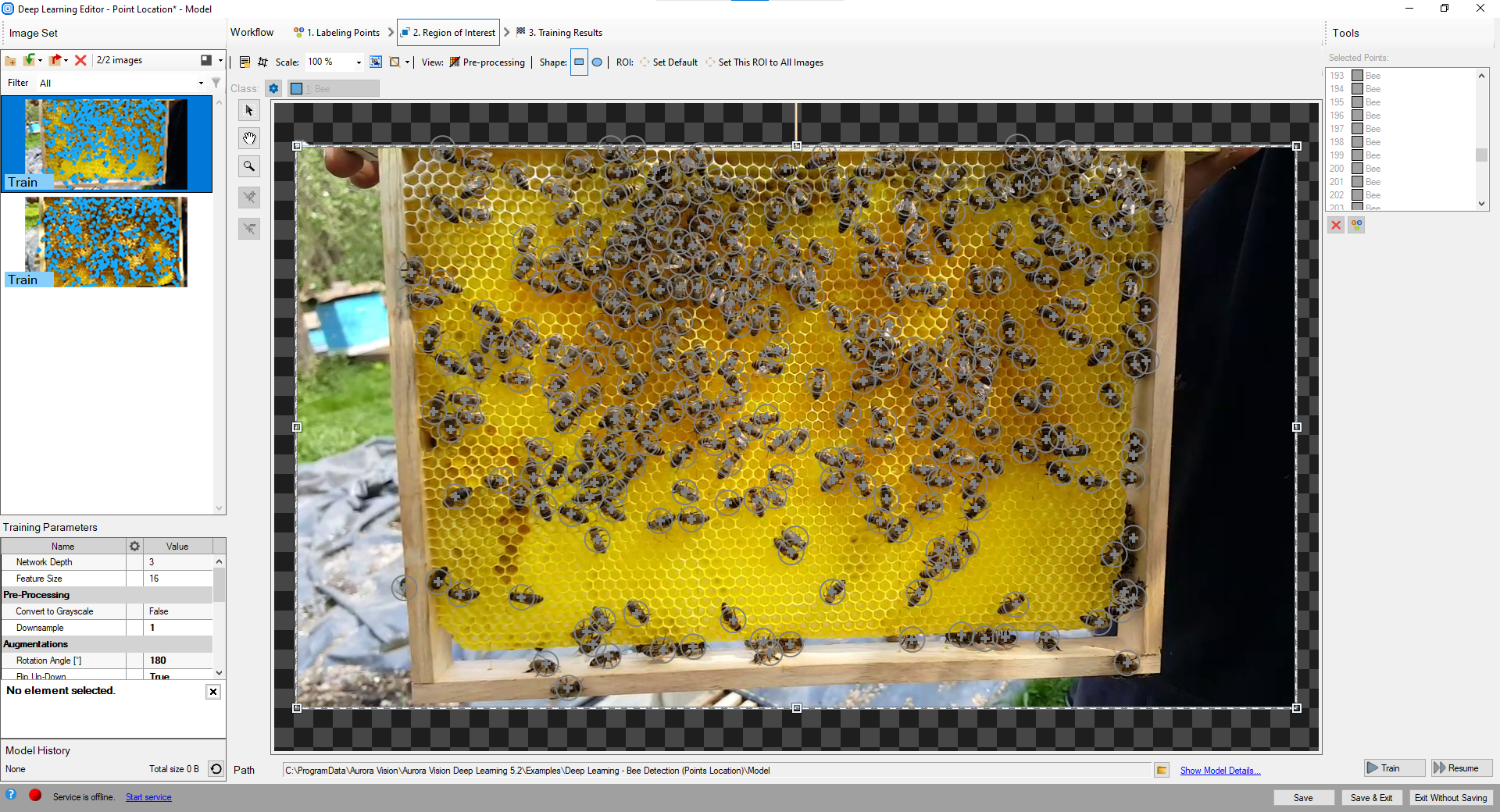
関心領域の変更
4. トレーニングパラメータの設定
- ネットワークの深さ – 事前定義されたネットワーク アーキテクチャ パラメータ。 より複雑な問題の場合は、さらに深いレベルが必要になる場合があります。
- 機能のサイズ – 小さな物体または特徴的な部分のサイズ。 画像に異なるスケールのオブジェクトが含まれている場合は、平均的なオブジェクト サイズよりわずかに大きい特徴サイズを使用することを推奨します。ただし、最適な結果を得るには、さまざまな値を試す必要がある場合があります。
- 停止条件 – トレーニング プロセスをいつ停止するかを定義します。
詳細については、ディープ ラーニング – をご覧ください。 パラメータを設定します。
拡張パラメータに関する詳細。 ディープ ラーニング – 拡張
5. トレーニングの実行
トレーニング中に、トレーニング エラーと検証エラーという 2 つの主要な系列が表示されます。 両方のチャートに同様のパターンがあるはずです。 3 番目のシリーズの前にトレーニングが実行された場合、以前の検証エラーも表示されます。
より詳細な情報がグラフの下に表示されます。
- 現在の反復番号
- 現在のトレーニング統計 (トレーニングおよび検証エラー)
- 処理されたサンプルの数
- 経過時間
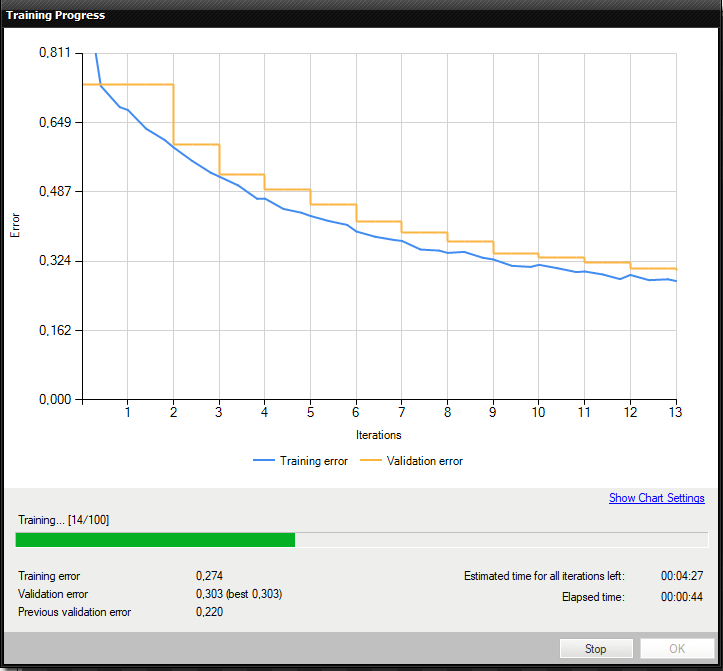
トレーニング ポイントの位置モデル
トレーニングは長いプロセスになる場合があります。 この間、トレーニングを停止することができます。 モデルが存在しない場合 (最初のトレーニング試行)、検証精度が最も高いモデルが保存されます。 トレーニングを継続的に試行すると、古いモデルを置き換えるかどうかをユーザーに尋ねるプロンプトが表示されます。
6. 結果の分析
ウィンドウにはポイント位置の結果が表示されます。 検出された点は画像の上に表示されます。 各検出は次のデータで構成されます。
- 視覚化されたポイント座標
- クラス (色で識別)
- 信頼スコア
評価: この画像 ボタンと 評価: すべての画像 ボタンを使用して、提供された画像上でポイントの位置を特定できます。 新しいトレーニング画像やテスト画像をデータセットに追加した後、または対象領域を変更した後に役立つ場合があります。
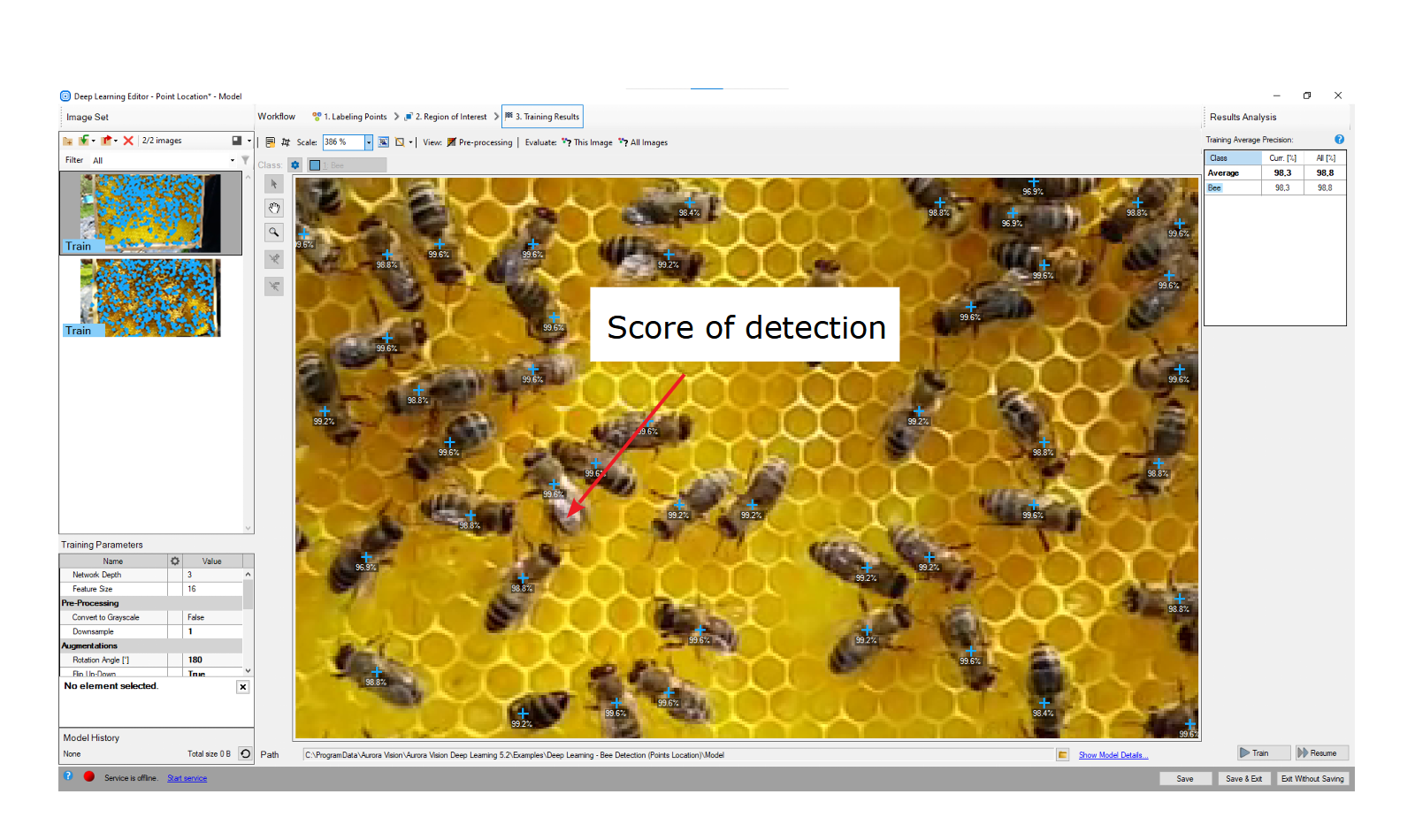
トレーニング後に視覚化されたポイント位置の結果
学習した情報を一般化するネットワークの能力を向上させるために、(タスクに適した) データ拡張を使用することを強くお勧めします。 それでも満足のいく結果が得られない場合は、次の標準的な方法を使用してモデルのパフォーマンスを向上させることができます。
- 特徴サイズの変更
- より多くのトレーニング データを提供する
- トレーニングの反復回数を増やす
- ネットワークの深さを増やす。
Locating objects
このツールでは、ユーザーはシーン内のオブジェクトの境界となる四角形を描画し、そのクラスを指定する必要があります。 これらの画像と四角形は、入力画像内のオブジェクトの位置を特定して分類するモデルをトレーニングするために使用されます。 このツールでは、インスタンスのセグメント化に必要なほど正確にユーザーがオブジェクトをマークする必要はありません。
1. クラスの定義
まず、ユーザーは、モデルがトレーニングされ、後で検出に使用されるオブジェクトのクラスを定義する必要があります。 オブジェクト ロケーション モデルは、単一クラスだけでなく複数クラスのオブジェクトも処理できます。
クラス エディターは、[クラス エディター] ボタンの下で使用できます。
クラスを管理するには、[追加]、[削除]、または [名前変更] ボタンを使用できます。 各クラスの色は、[色の変更] ボタンを使用して変更できます。
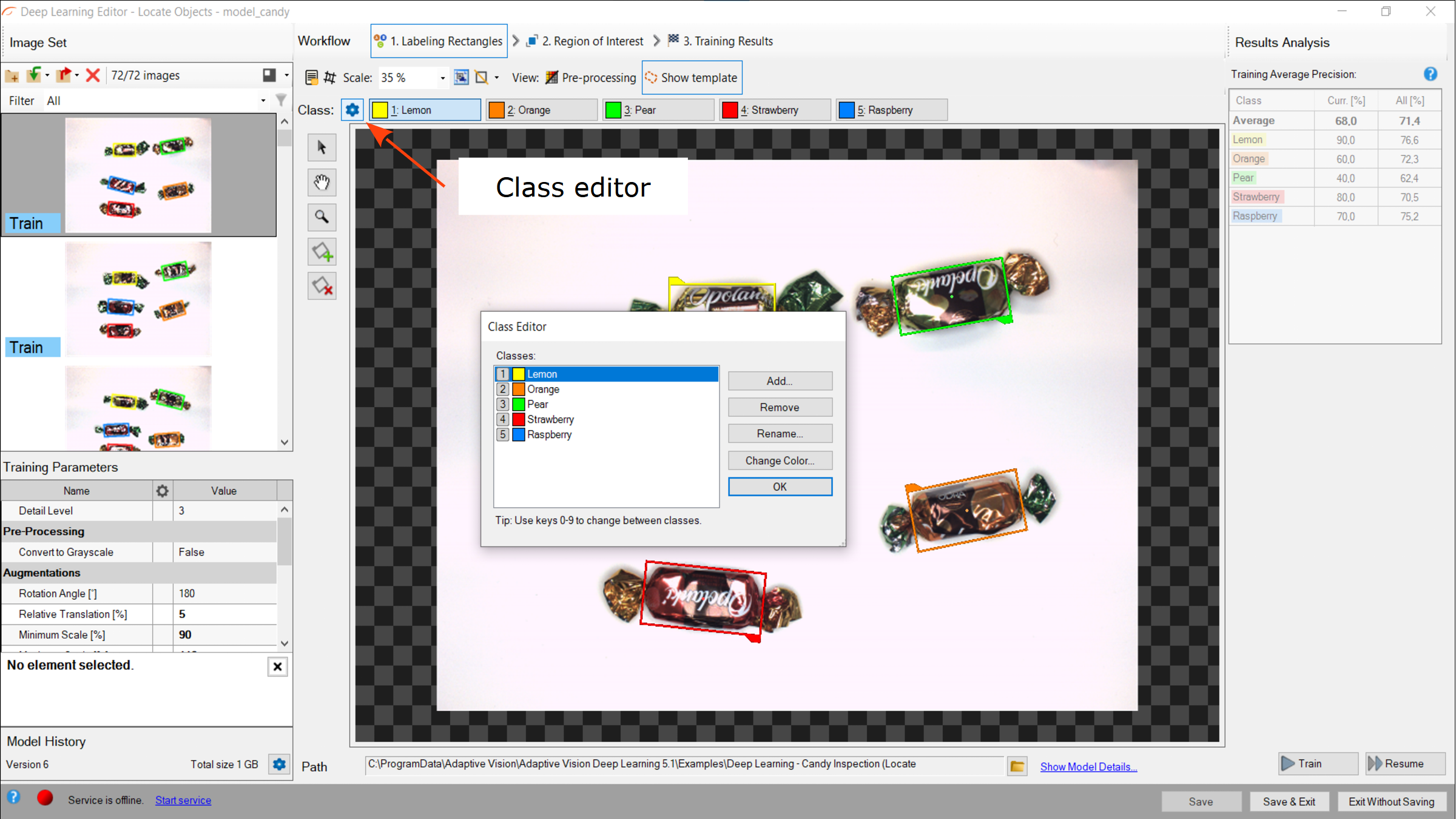
Using Class Editor.
2. 境界四角形をマークする
トレーニング画像を追加し、クラスを定義した後、ユーザーは画像内の四角形をマークする必要があります。
オブジェクトをマークするには、クラス ツールバーから適切なクラスをクリックし、[四角形の作成] ボタンをクリックする必要があります。 長方形は、選択したクラスに対して以前に定義したものと同じ色になります。
長方形は画像領域上で直接選択できます。 選択した四角形は、オブジェクトに合わせて移動、回転、サイズ変更したり、削除したり ([領域の削除] ボタン)、クラスを変更したり (四角形を右クリック » [クラスの変更] ボタン) することができます。
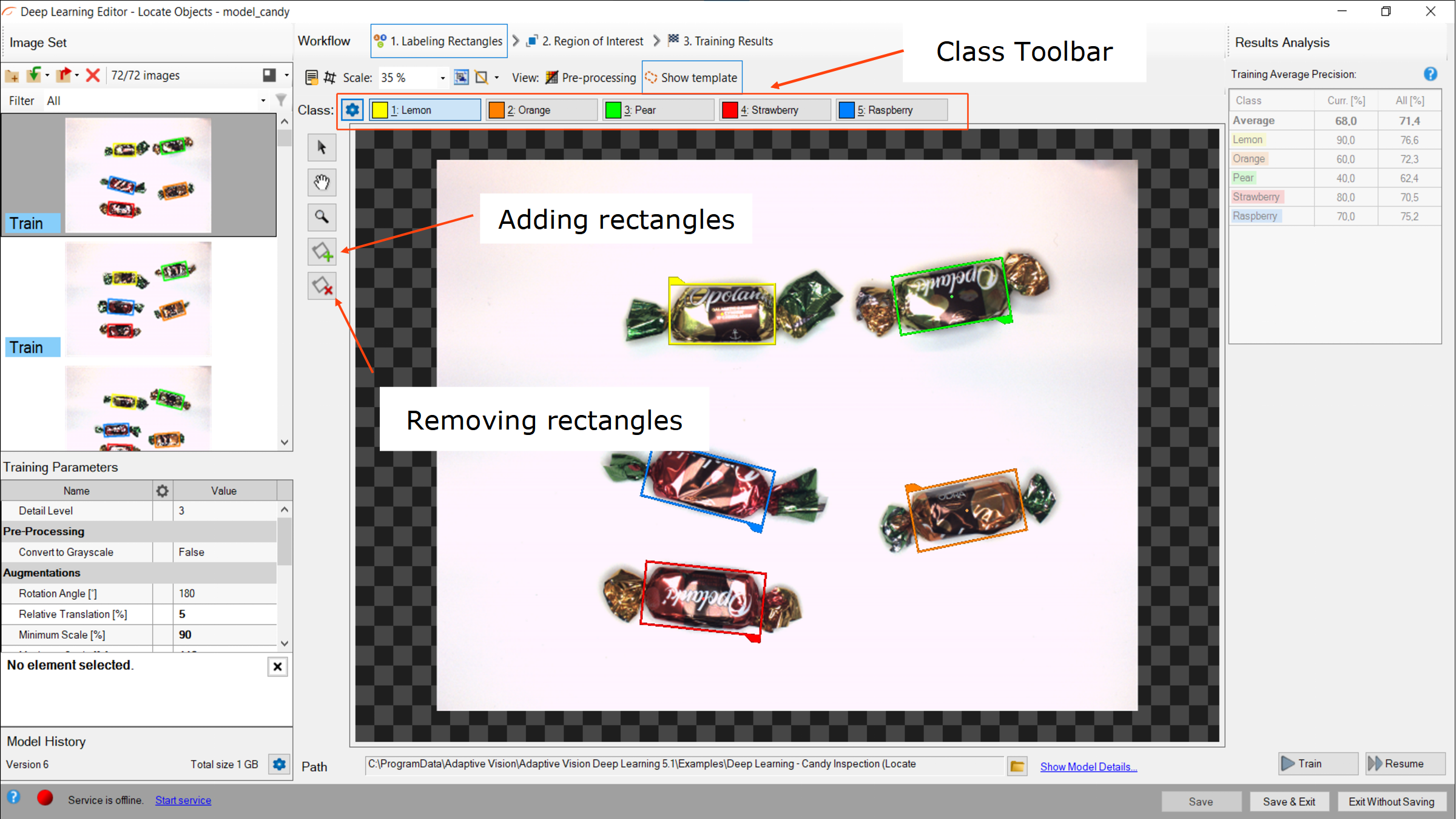
四角形にマークを付ける
3. 関心領域の縮小
関心領域を縮小して画像の重要な部分のみに焦点を当て、トレーニング プロセスを高速化します。 デフォルトでは、対象領域には画像全体が含まれます。
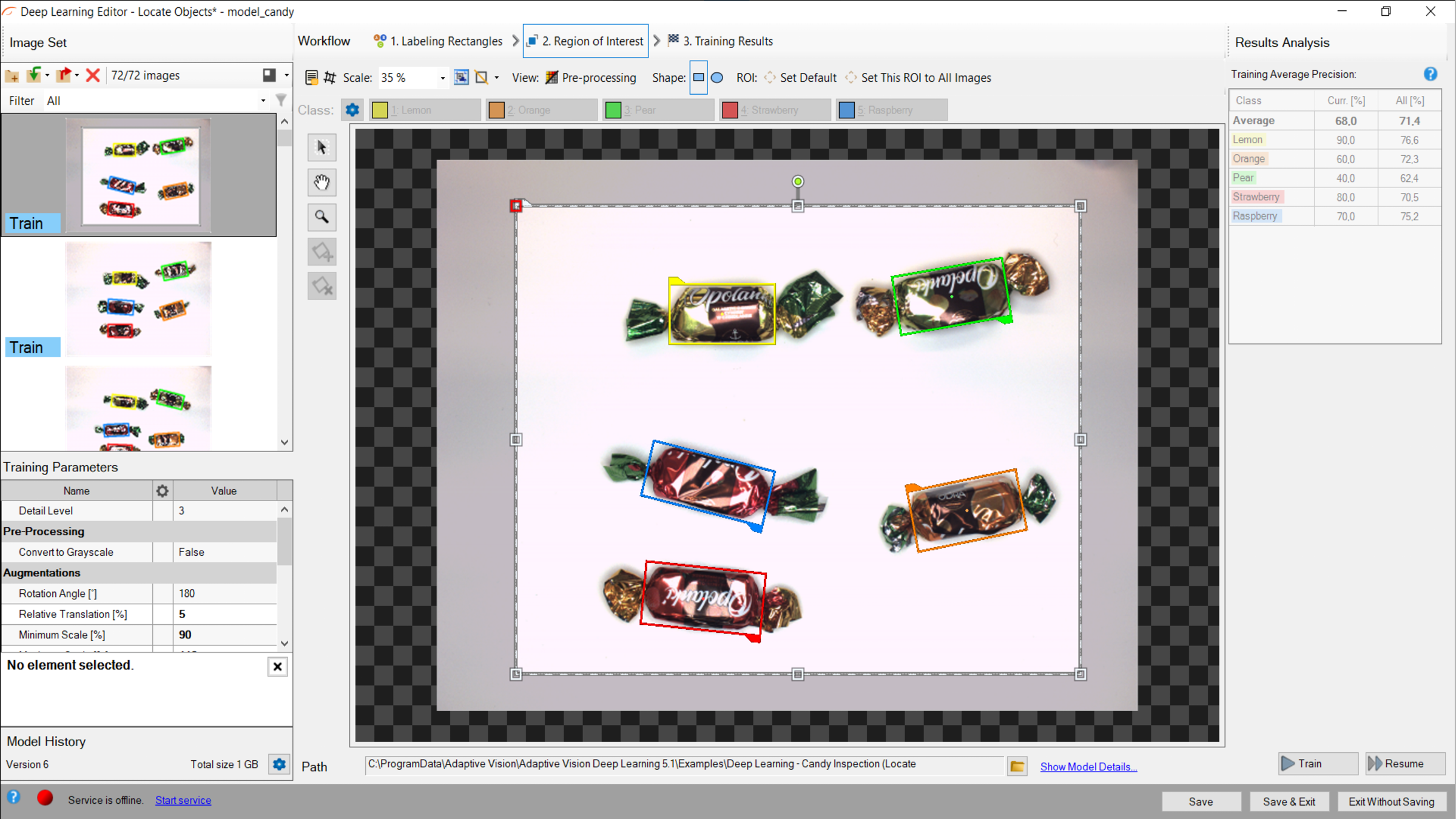
関心領域の変更
4. トレーニングパラメータの設定
- 詳細レベル – 特定の分類タスクに必要な詳細レベル。 ほとんどの場合、デフォルト値の 3 が適切ですが、異なるクラスの画像が小さな特徴によってのみ区別できる場合は、このパラメータの値を増やすと分類結果が改善される可能性があります。
- 停止条件 – トレーニング プロセスをいつ停止するかを定義します。
詳細はDeep Learning – Setting parametersはご覧ください。
拡張パラメータの詳細: Deep Learning – Augmentation
5. トレーニングの実行
トレーニング中に、トレーニング エラーと検証エラーという 2 つの主要な系列が表示されます。 両方のチャートに同様のパターンがあるはずです。 3 番目のシリーズの前にトレーニングが実行された場合、以前の検証エラーも表示されます。
より詳細な情報がグラフの下に表示されます。
- 現在の反復番号、
- 現在のトレーニング統計 (トレーニングおよび検証エラー)、
- 処理されたサンプルの数、
- 経過時間。
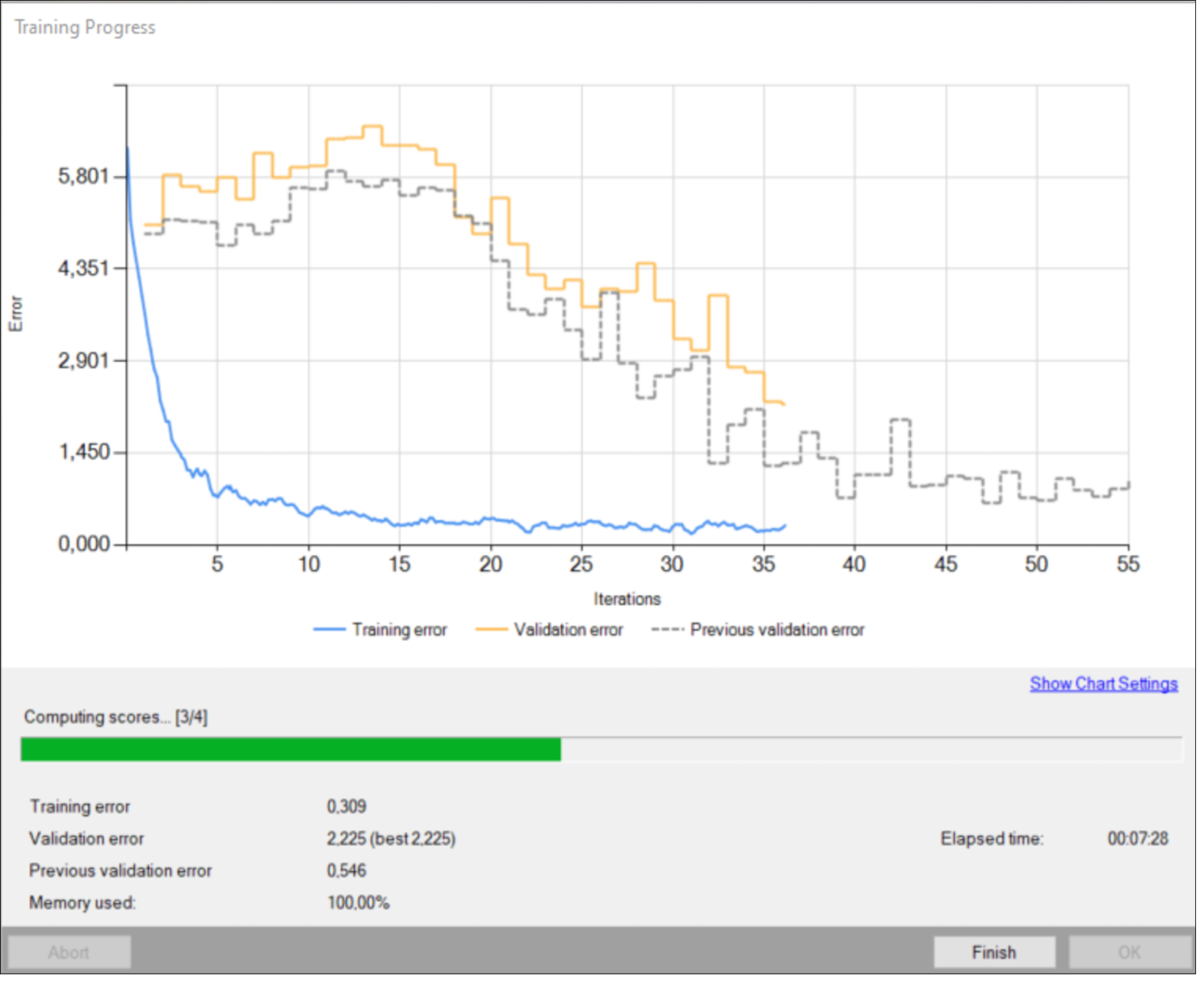
トレーニング オブジェクトの位置モデル。
トレーニングは長いプロセスになる場合があります。 この間、トレーニングを停止することができます。 モデルが存在しない場合 (最初のトレーニング試行)、検証精度が最も高いモデルが保存されます。 トレーニングを継続的に試行すると、古いモデルを置き換えるかどうかをユーザーに尋ねるプロンプトが表示されます。
6. 結果の分析
ウィンドウにはポイント位置の結果が表示されます。 検出された点は画像の上に表示されます。 各検出は次のデータで構成されます。
- 視覚化された四角形(オブジェクト)の座標
- クラス (色で識別)、
- 信頼スコア。
評価: この画像 および 評価: すべての画像 ボタンを使用して、提供された画像上でオブジェクトの位置を特定できます。 新しいトレーニング画像やテスト画像をデータセットに追加した後、または対象領域を変更した後に役立つ場合があります。
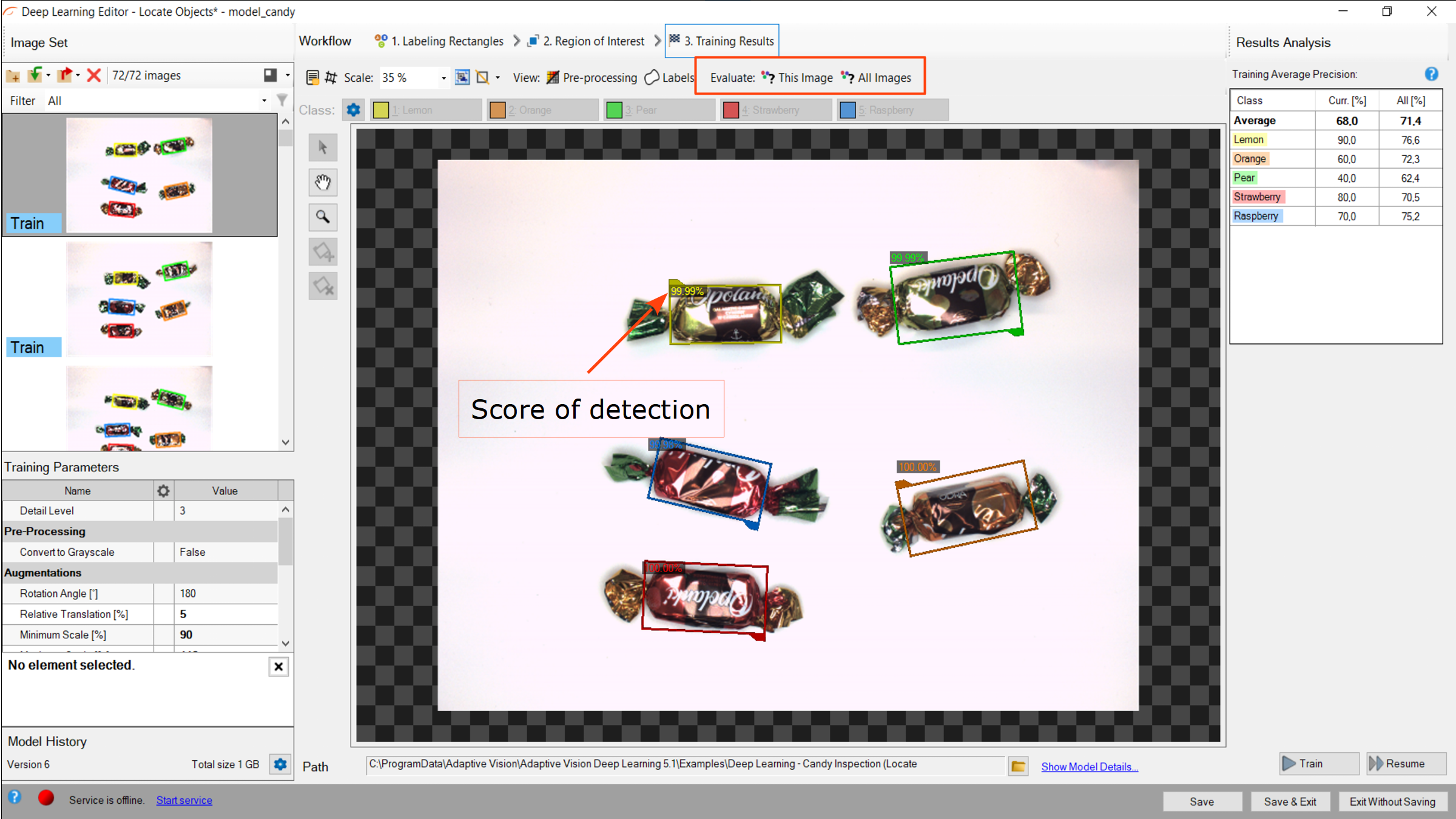
トレーニング後に視覚化されたオブジェクト位置の結果
学習した情報を一般化するネットワークの能力を向上させるために、(タスクに適した) データ拡張を使用することを強くお勧めします。 それでも満足のいく結果が得られない場合は、次の標準的な方法を使用してモデルのパフォーマンスを向上させることができます。
- 詳細レベルの変更
- より多くのトレーニング データを提供する
- トレーニングの反復回数を増やす、またはトレーニングの期間を延長する
こちらも参照してください:
- Machine Vision Guide: Deep Learning – ディープラーニング技術の概要
- Deep Learning Installation – Aurora Vision Deep Learning のインストールと構成