
高速な画像解析の最適化
一般的なルール
ルール1: 不要なものは計算しないこと。
- タスクに適した画像解像度を使用してください。解像度が高いほど処理が遅くなります。
- 画像処理のinRoi入力を使用して、次の処理ステップで必要なピクセルのみを計算します。
- 一定の領域で複数の画像処理操作が連続して発生する場合は、最初にCropImageを使用する方が良い場合があります。
- UInt8(8ビット)以外のタイプの画像を過度に使用しないでください。
- 色情報が処理されていない場合、マルチチャンネルの画像を使用しないでください。
- 一度だけ計算できるものがある場合は、それらをメインプログラムループの前または別のプログラムに移動します。
以下は、このアドバイスを実装した「Main」マクロフィルタの典型的な構造の例です。最初のマクロフィルタは一度だけの計算を担当し、2番目はメインプログラムループを実装しています。
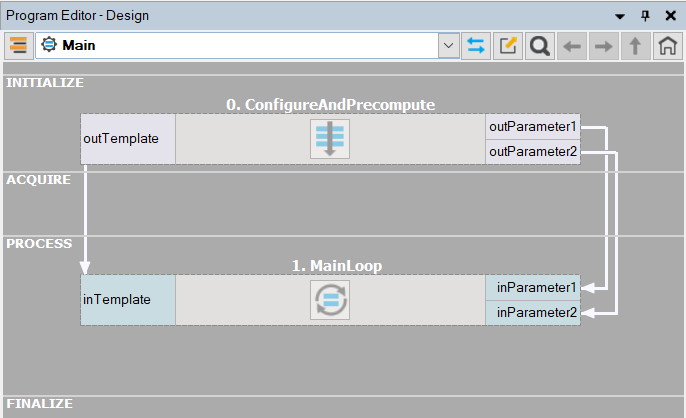
一度だけの計算とメインループを分離した典型的なプログラム構造。
ルール2: シンプルな解決策を優先すること。
- テンプレートマッチングはよりシンプルなテクニック(Blob Analysisや1D Edge Detection)で十分な場合は使用しないでください。
- ピクセル単位の画像解析テクニック(Region Analysis)およびBilinearではなくNearest Neighbourの画像補間を優先してください。
- プログラムパイプラインの早い段階で高レベルの情報を抽出することを検討してください。たとえば、Regionsを処理する方がImagesよりもはるかに高速です。
ルール3: ユーザーインターフェースの影響に注意すること。
- 開発環境ではプレビューウィンドウにデータを表示するのに時間がかかります。性能がランタイム環境で期待できるものに近づけるには、Program » Previews Update Mode » Disable Visualizationを選択してください。
- ランタイム環境では、画像表示にはVideoBoxコントロールを使用してください。これは高度に最適化されており、1秒間に何百もの画像を表示できます。
- VideoBoxコントロールを使用する場合は、特に表示する画像が大きい場合はSizeMode: Normalの設定を優先してください。また、DownsampleImageまたはResizeImageも検討してください。
- Update Data Previews Once an Iterationオプションを優先してください。
- Diagnostic Modeに注意してください。速度をテストする必要がある場合はオフにします。
- Statisticsウィンドウが提供する情報に注意してください。プログラムを最適化する前に、本当に最適化が必要かどうかを確認してください。
ルール4: データフローモデルの影響に注意すること。
データフロープログラミングは、高度なツールを使用して画像解析が主要な部分である限り、標準のC++プログラミングとほぼ同じ速度で高速なマシンビジョンアプリケーションを作成できます。 これには、高レベルのツールを使用し、画像解析が主要な部分であるという前提を満たす必要があります。 一方で、多くの単純なフィルタを使用して高数のピクセル、ポイント、または小さなブロブを処理するような低レベルのプログラミングタスクの場合、 すべての解釈言語はC++よりも著しく遅くなります。
- パフォーマンスが重要な低レベルのプログラミングタスクにはユーザーフィルタを検討してください。
- 算術フィルタ(例:AddIntegersまたはDivideReals)よりも、数式ブロックを優先してください。
- 多くの低レベルのフィルタや数式(パスの個々の点の座標を計算するなど)よりも、 少ない数の高レベルなフィルタ(例:RotatePath)を使用してください。
- 非プリミティブ型(ImageやRegionなど)の非プリミティブ型と一緒にMergeDefaultやChooseByPredicateなどの低レベルのフィルタを使用するのを避けてください。 フィルタは少なくとも1つの入力オブジェクトを完全にコピーします。代わりにVariant Step Macrofiltersを使用することをお勧めします。
- 変換との接続(矢印の先にドットが付いている)に注意してください。いくつかの場合(例:RegionToImage)では、追加の計算が発生することがあります。 同じ変換が何度も使用される場合は、直接変換フィルタを使用する方が良い場合があります。
- 配列接続を持つフィルタのシーケンスは、多くのデータを出力に生成する可能性があります。最終結果だけが重要な場合は、
すべての接続が基本的なものになるように、配列モードで実行されるマクロフィルタを抽出することを検討してください。例:
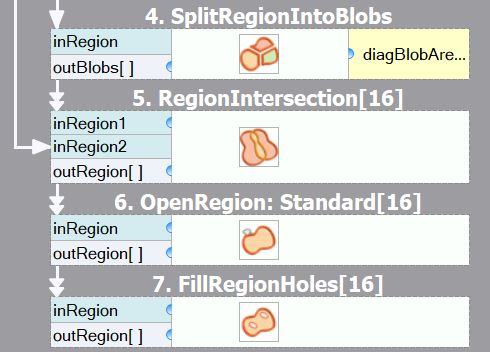
最適化前: いくつかの中間結果の配列があります。

最適化後: 最終的な配列のみが計算され、メモリ消費が削減されています。マクロフィルタの入力はRegion型であることに注意してください。
共通の最適化のヒント
上記の一般的なルールに加えて、特定のフィルタやテクニックに関連するいくつかの共通の最適化のヒントもあります。以下はチェックリストです。
- テンプレートマッチング: オブジェクト全体をテンプレート領域としてマークせず、ユニークな形状を持つ一部をマークしてください。
- テンプレートマッチング: 高いピラミッドレベルを優先し、つまりinMaxPyramidLevelをAutoまたは4から6のような高い値に設定してください。
- テンプレートマッチング: inEdgePolarityModeをIgnoreに設定せず、inEdgeNoiseLevelをLowに設定してください。
- テンプレートマッチング: inMinScoreの入力値を可能な限り高い値に設定してください。
- テンプレートマッチング: 高解像度の画像を処理する場合は、inMinPyramidLevelを1または2に設定することを検討してください。
- テンプレートマッチング: テンプレートマッチングモデルを作成する際は、inMinAngleおよびinMaxAngleの入力で角度の範囲を制限してください。
- テンプレートマッチング: 回転とスケーリングを同時に許可すると、高速な処理は期待できません。また、モデルの作成には多くの時間がかかるか、メモリ不足のエラーが発生する可能性があります。
- テンプレートマッチング: inSearchRegionを制限することを検討してください。手動で設定することもできますが、テンプレートマッチングの前にリージョン分析テクニックを使用すると助けになることがあります。
- テンプレートマッチング: inEdgeCompletenessを減少させ、速度を向上させる代わりに信頼性を低下させることができます。これは、ピラミッドを高くできない場合に情報が失われるためです。
- これらのフィルタはメインのプログラムループで使用しないでください:CreateEdgeModel1、CreateGrayModel、TrainOcr_MLP、TrainOcr_SVM。
- 常に同じ方法で画像を変換する場合は、Image Spatial Transforms Mapsカテゴリのフィルタを使用してください。Image Spatial Transformsではなく。
- 任意の形状のカーネルを使用する画像ローカル変換は使用しないでください:DilateImage_AnyKernel、ErodeImage_AnyKernel、SmoothImage_Mean_AnyKernel。 "_AnyKernel"サフィックスのない代替手段を検討してください。
- SmoothImage_Medianは特に遅い場合があります。可能であれば、ガウスまたは平均の平滑化を使用してください。
アプリケーションのウォームアップ(高度)
トリガーされたカメラを使用する産業用アプリケーションにおいて重要な実践的な問題の1つは、 プログラムの最初の反復がすでにフルスピードで実行される必要があることです。ただし、 最初の反復で実行される追加の計算が考慮される必要があります。
- 出力データのメモリバッファ(特に画像)が割り当てられます。
- メモリバッファがキャッシュメモリに読み込まれます。
- 外部DLLライブラリがオペレーティングシステムによってディレイロードされます。
- ブランチ予測などの現代のCPUメカニクスがトレーニングされます。
- 外部デバイス(例:カメラ)との接続が確立されます。
- 一部のフィルタ、特に1D Edge DetectionおよびShape Fittingからのもの、がいくつかのデータを事前に計算します。
これらは、簡略化されたデータフロープログラミングモデルと コンピュータおよびオペレーティングシステムの現代的なアーキテクチャの両方から発生するものです。これらのうちの一部は、 Aurora Vision Libraryの使用で解決できる場合がありますが(詳細は:Aurora Vision Libraryを使用するタイミングは?)、 Aurora Vision Studioでも役立つ可能性があるイディオムがあります。「アプリケーションのウォームアップ」と呼ばれ、 アプリケーションが操作段階に切り替わる前にテスト画像(録画済み)で1回または複数回反復を実行することです。 これは、次の「GrabImage」バリアントマクロフィルタを使用して達成できます:
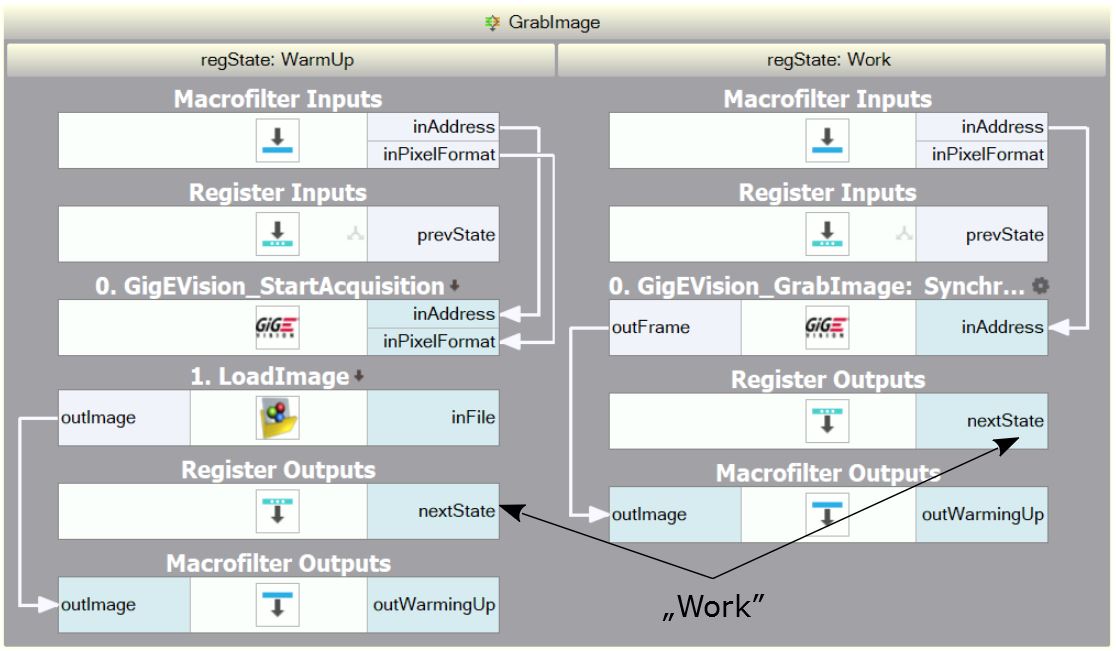
アプリケーションのウォームアップに使用される「GrabImage」マクロフィルターの例。
上記に示す「GrabImage」バリアントマクロフィルタは、アプリケーションのウォームアップをどのように実現できるかの例です。 「WarmUp」バリアントで動作を開始し、カメラを初期化してテストイメージを生成します(これは正確には カメラから取得される画像と同じ解像度および形式を持っています)。その後、「Work」バリアントに切り替え、標準の画像 取得フィルタを使用します。また、ウォームアップ段階で出力シグナルを抑制するために使用できる 追加の出力outIsWarmingUpもあります。
並列計算の設定
Aurora Vision Studioのフィルタは、複数のスレッドを内部で使用して、マルチコアプロセッサの全力を発揮します。デフォルトでは、物理プロセッサの数だけスレッドを使用します。これはほとんどのアプリケーションにとって最適な設定ですが、一部のケースでは別のスレッド数の方が実行が速くなる場合があります。最大のパフォーマンスが必要な場合は、ControlParallelComputing フィルタを使用して、スレッド数を増減させて実験することが推奨されます。具体的には次の点に注目します:
- スレッド数が物理プロセッサの数よりも多い場合、Hyper-Threadingテクノロジを利用できる可能性があります。
- スレッド数が物理プロセッサの数よりも少ない場合(たとえば、クアッドコアマシンで3つのスレッド)、システムはバックグラウンドスレッド(画像取得、GUI、他のプロセスによる演算など)に使用可能な少なくとも1つのコアを持っているため、その応答性が向上する可能性があります。
画像メモリプールの設定
フィルタのパフォーマンスに影響を与える重要な要因の1つはメモリの割り当てです。Aurora Vision Studioで利用可能なほとんどのフィルタは、連続した反復の間にメモリバッファを再利用し、これはパフォーマンス向上に非常に有益です。ただし、一部のフィルタは引き続き一時的な画像バッファを割り当てることがあります。そうでなければ、それらを使用するのが不便になる可能性があります。この制限を克服するためには、ControlImageMemoryPools フィルタがあり、一時的な画像のためにカスタムメモリアロケータをオンにできます。
また、プログラムの最初の反復が開始される前に画像メモリを事前に割り当てる方法もあります。この目的のために、プログラムの最後に InspectImageMemoryPools フィルタを使用し、そしてプログラムが実行された後にその outPoolSizes の値を、プログラムの最初に実行される ChargeImageMemoryPools フィルタの入力にコピーします。これにより、最初の反復のパフォーマンスが向上することがあります。
GPGPU/OpenCL計算の使用
Aurora Vision Studioの一部のフィルタでは、計算をOpenCL対応デバイス(グラフィックカードなど)に移動して実行速度を向上させることができます。適切な初期化後、OpenCL処理は対応するフィルタによって完全に自動的に実行され、使用パターンは変更されません。どのフィルタがOpenCL処理をサポートし、その要件は何かを知るには、フィルタのドキュメントの「ハードウェアアクセラレーション」セクションを参照してください。OpenCLデバイスに切り替えた場合の実際のパフォーマンスは、常に適切な測定によって対象のシステムで検証する必要があります。
Aurora Vision StudioでOpenCL処理を使用するには、以下が必要です:
- OpenCL C言語をバージョン1.1以上でサポートするターゲットシステムにインストールされた処理デバイス、
- システムにインストールされた適切で最新のデバイスドライバ、
- ベンダーが提供する適切なOpenCLランタイムソフトウェア。
OpenCL処理は、例えば以下のフィルタでサポートされています:RgbToHsi、HsiToRgb、 ImageCorrelationImage、DilateImage_AnyKernelなど。
フィルタでOpenCL処理を有効にするには、プログラムの最初に InitGPUProcessing フィルタを実行する必要があります。詳細については、そのフィルタのドキュメントを参照してください。
Aurora Vision Libraryを使用するタイミング
Aurora Vision Libraryは、C++プログラマ向けの別の製品です。提供される関数のパフォーマンスは、大まかに言って、Aurora Vision Studioが提供するフィルタのパフォーマンスと同じです。ただし、コンパイルされたコード全体のパフォーマンスが優れている場合があります。
Case 1: 単純な操作の高い数
Studioの各フィルタの実行ごとに約0.004ミリ秒のオーバーヘッドがあります。この値は非常に少ないように思えるかもしれませんが、各反復で50のブロブを分析し、各ブロブごとに20のフィルタを実行するアプリケーションを考えると、合計で4ミリ秒になる可能性があります。これはすでに無視できないかもしれません。 これが大きなアプリケーションの一部である場合、User Filtersが正しい解決策かもしれません。ただし、これがアプリケーション全体の動作である場合、ライブラリを使用する必要があります。
Case 2: メモリの再利用が大きな画像の場合
Aurora Vision Studioの各フィルタは、その出力データを出力ポートに保持します。連続するフィルタはこのメモリを再利用せず、代わりに新しいデータを作成します。これは、ユーザーがすべての中間結果を見ることができるため、アルゴリズムを効果的に開発するのに非常に便利です。ただし、アプリケーションが非常に大きな画像(例:10メガピクセル以上のラインスキャンカメラから)を複雑に処理する場合、メモリの再利用の問題が重要になるかもしれません。この場合、Aurora Vision Libraryは有用であり、C++プログラミングのレベルでメモリバッファを完全に制御できます。
Aurora Vision Libraryはまた、インプレースデータ処理を実行できるようにします。つまり、新しいオブジェクトを作成する代わりに、入力データを直接変更します。多くの単純な画像処理操作は、この方法で実行できます。特に、Image Drawing 関数やROI内の画像変換などが大幅にパフォーマンス向上する可能性があります。
Case 3: 最初の反復前の初期化
Aurora Vision Studioのフィルタは最初の反復で初期化されます。これは、たとえば画像メモリバッファが割り当てられるときなどです。なぜなら、最初の画像が取得されるまで、フィルタは必要なメモリの量を知らないからです。しかし、アプリケーションは特定の条件に最適化でき、最初の反復が遅くならないことが重要な場合があります。C++プログラミングのレベルでは、事前に割り当てられたメモリバッファと、一部のフィルタの別々の初期化(特に1D Edge DetectionおよびShape Fittingフィルタ、および画像取得およびI/Oインターフェースの場合)でこれを実現できます。 以下も参照してください。 Application Warm-Up.