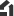
光による次世代コンピューティング
製品名
PACE
製品名
PACE
シリコンフォトニクスがもたらす次世代の光演算技術
高速な行列演算を高いワットパフォーマンスで実現




- 高密度シリコンフォトニクスによる次世代光演算アクセラレータ
- マッハツェンダ干渉計(MZI)をベースとした光演算ユニットをパッケージ化
- CMOSプロセスを使って微細変調回路と導波路をオンチップ
- 64×64のビット行列演算を高速かつ低遅延に実行可能
- GPUよりも高い演算力を遥かに小さい消費電力で実現
- 最大カット問題をGPUよりも800倍早く解く事が可能
Lightelligence社が開発した「PACE」は光コンピューティングの革新的なエンジンであり、従来のCPUやGPUとは異なる高速演算を実現します。PACEは12,000以上のマッハチェンダ干渉計ベースの光演算ユニットを備え、光の伝播のみで演算することができるため、驚異的な低遅延/低消費電力での演算が可能です。
PACEは光コンピューティングがNP完全問題を高速に解決する優位性を立証するために開発された評価ユニットです。64×64のビット行列演算に特化しており、GPUの800倍以上の速さで最大カット問題を解決します。64ノードのイジングモデルへのアニーリング処理では、1回あたりたったの3nsで実行可能。NP完全問題を解決するためには繰り返し行列演算を行う必要があるため、処理時間が短くなる光コンピューティングに優位性がある事を実証しています。
光積和演算回路 “oMAC - Optical Multiply Accumulate”
光を使った乗算ユニットoMACは以下の様に光信号と電気信号の相互変換を行っています。
オンチップSRAMから入力されたベクトル値(0 or 1)は、デジタル-アナログコンバーターを経由してアナログ値に変換されます。その後、アナログ値に応じてマイクロバンプを介して対応する光モジュールの光を変調し、光ベクトル値へと変換されます。光ベクトル値はMZIによる光学マトリクスを通過する事で相互作用し、新たな光ベクトル値が合成されます。最後に、合成された光ベクトル値をフォトデバイスのアレイで検出し、光の強度を電気に変換します。変換された電気信号はマイクロバンプを介して再び電子チップに戻り、トランスインピーダンス増幅器とアナログ-デジタルコンバーターを経由してデジタル値として復元されます。
| PACE | |
|---|---|
| 対応プロセッシング | 64×64 行列積 |
| システムクロック | 1GHz |
| データ精度 | INT8 |
| 理論演算能力 | 8TOPS |
| 消費電力 | 2W |
| ワットパフォーマンス | 4TOPS/W |
| oMAC演算遅延 | 150ps |
| 光コネクタ | FCコネクタ 4ポート |
| 接続インターフェイス | GigabitEthernet(1000BASE-T) |
| 内部OS | Linux Kernel5.10(aarch64) |
| 付属レーザーユニット | |
| 波長 | 1330nm |
| レーザーパワー | 30mW |
| レーザークラス | Class 3B |
| 光コネクタ | FCコネクタ |
| 制御用インターフェイス | USB2.0 |
PACEの演算プロセス
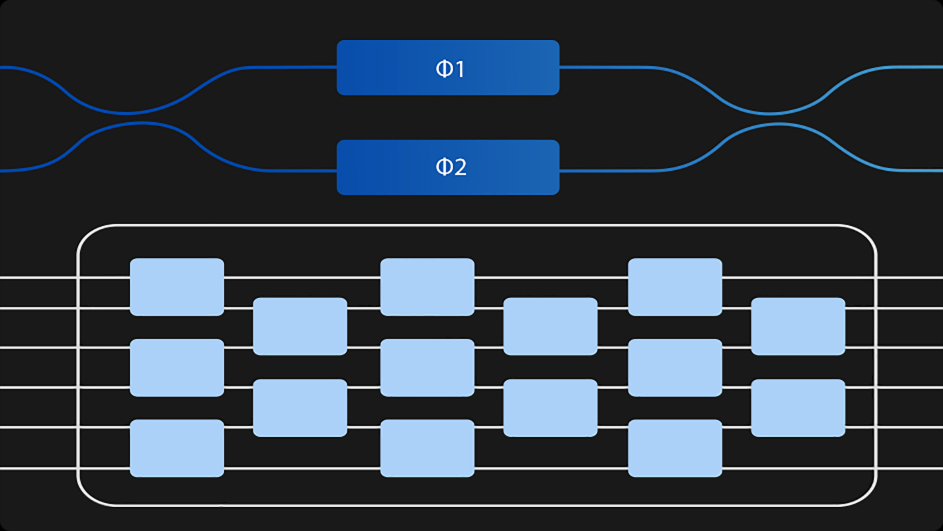
PACEは、2次元に配置された64×64のスピンのイジング問題を解決するために設計されています。各スピン間の距離は64x64の行列(距離行列H)で表され、各スピンの状態は1×64のベクトル(状態ベクトルS)で表されます。
最適解の探索アルゴリズム
- (1)状態ベクトルSをランダムに初期化する
- (2)5000回のループ処理を実行し、以下の手順を反復実行する。
- 入力された状態ベクトル値を電気信号から光信号へ変換し、ランダムなノイズ値を付加する
- 光演算チップ上で行列積を実施し、新しい状態ベクトル値を取得する
- 新しい状態ベクトル値を光信号から電気信号に変換し、次のループ処理で再利用する
- (3)5000回のループ処理の最後に最終エネルギー値と、各行列での状態ベクトル値を取得します。
GPUより遥かに高速な演算能力

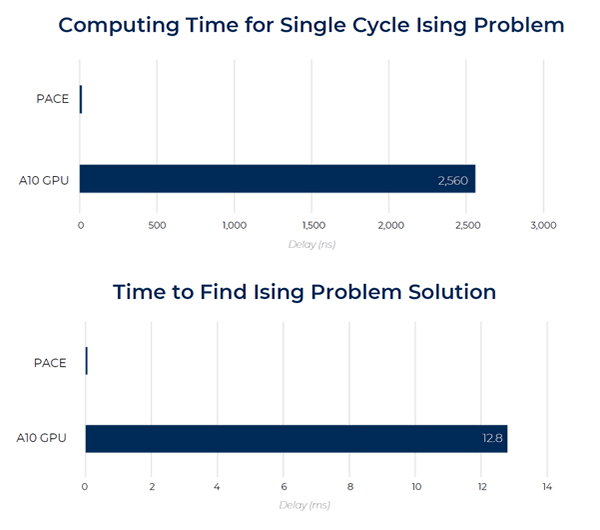
疑似量子アニーリングによるイジング問題の解決には数多くの演算を行う必要があります。PACEではイジング問題での最適解の探索において、NVIDIA社のAI処理専用GPUのA10よりも800倍速いパフォーマンスが確認されています。光コンピューティングでは光の伝播のみで演算が完結するため、この様に古典的な演算プラットフォームに比べ圧倒的な応答性能を得る事が可能です。また、光るだけで演算できるためGPUに比べ遥かに少ない消費電力で動作します。
| 商品コード(型番) | 構成/内容 | 価格 | |
|---|---|---|---|
| アクセラレーター | PACE | 光コンピューティングユニット / レーザーユニット×4個 | お問い合わせ |
